Structure du format de fichiers PE - Application avec le Notepad
(Remarque : des éléments de ce tut ont déjà été abordé dans d'autres Mementos. Ce tut aborde en détail et depuis le début les notions sur les exes.)Note importante: Pour ne pas s'emméler les pinceaux, DANS TOUT LE TUT, tous les chiffres/nombres/valeurs en hexa seront précédés par un "0x". Le "0x" n'est pas un nombre, mais une information pour dire "Attention, ce qui suit juste après est en hexadécimal". Les nombres décimaux seront écrits normalement.
Exemple :
- Un bloc de 0x10 bytes = Un bloc contenant 16 (en
décimal) bytes.
- Il y a 10 lignes dans ce bloc = Le bloc contient
10 (en décimal) lignes.
Aujourd'hui on va s'attaquer aux exes. Les utilisateurs de Mac nous reprochent toujours de devoir mettre la main dans le camboui en tant qu'utilisateurs de PC, et ça tombe bien car c'est ce qu'on va faire!!! Quant aux utilisateurs de Mac, qu'ils restent avec leurs belle boite bien chère tout fermée, et qu'ils continuent à faire ce qu'on leurs dit de faire et de ne surtout pas réfléchir... Et en plus ils s'en vantent :) les c...!
Bon en fait, je suis mauvaise langue car il y a quand
même des rassemblements comme le MacHack (Macaque!?!) aux States, où il
y a des gens qui n'ont rien à envier aux meilleurs coders,crackers.. de
PC.
C'est de bonne guerre ;p
Go!
Matos nécessaire:
- Une tête bien fraîche et réveillée (Comme toujours
!)
- On va travailler sur n'importe quel petit exe fournit par kro$oft, par
exemple le notepad. Donc vous en faites une copie de sécurité que l'on
va défoncer (yeaah!)
- Un éditeur hexa
- Procdump
- Un placard bien grand et bien solide :)
Tout d'abord vous enfermez la copine ( le copain s'il y a des filles qui s'initient au cracking! hello girls :) ), les parents, le frère, la soeur, le chien et le chat dans le placard. Et oui, jai dit bien grand et bien solide. Il y a du monde et il faut que ça tienne! Comme cela on a la paix, et on va pouvoir travailler tranquilloux.
On y va...
Tout bon crackeur doit très vite avoir une certaine notion des executables ne serait ce que pour savoir/comprendre ce qu'il faitquand il (elle) utilise Procdump par exemple! Je ne me prétend pas du tout être bon dans le domaine, mais je voudrais donner un minimum d'aperçu sur les exes.
Petit historique :)
Le système d'exploitation Windows NT version 3.1 a introduit un nouveau format de fichier executable appelé le format de fichier Portable Executable (PE). Ce nouveau format fut élaboré principalement à partir de la spécification du COFF (Common Object File Format - COFF entête et entête optionnel) en vigueur dans le monde Unix. De plus pour rester compatible avec les versions antérieures de MS-DOS et de Windows, le format PE comprend le familier en-tête MZ du MS-DOS.
Structure des fichiers PE
Le format de fichier PE est organisé comme un flux de données de manière linéaire. Il commence avec l'entête MS-DOS, le "program stub" en mode réel et la signature du PE. Ensuite, on trouve l'entête PE et le PE optionnel. Les sections sont déclarées dans un partie qui suit le PE optionnel.
On va aborder dans ce tut chacune des parties du PE (i.e. de l'executable) tels qu'elles s'enchainent quand on parcours de haut en bas l'executable sous un éditeur hexadécimal. Toute la structure et la composition d'un PE est donnée dans le fichier WINNT.H. Ce fichier est inclus dans toute application servant au développement d'applications windows.
On commence par ouvrir le notepad sous l'éditeur hexa.
Je rappelle que tout ce tut ne traite QUE du notepad.
De même, toutes les données en chiffres sont HEXADECIMALES.
Ainsi quand on visualise un soft sous un éditeur hexa, il est bon de connaitre les differentes sections que l'on peut apercevoir. Voici un petit aperçu depuis son début jusqu'à la fin:
ENTETE / DEBUT DE PROGRAMME
00000000 4D5A 9000 0300 0000 0400 0000 FFFF 0000 MZ..............
00000010 B800 0000 0000 0000 4000 0000 0000 0000 ........@.......
00000020 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000030 0000 0000 0000 0000 0000 0000 8000 0000 ................
00000040 0E1F BA0E 00B4 09CD 21B8 014C CD21 5468 ........!..L.!Th
00000050 6973 2070 726F 6772 616D 2063 616E 6E6F is program canno
00000060 7420 6265 2072 756E 2069 6E20 444F 5320 t be run in DOS
00000070 6D6F 6465 2E0D 0D0A 2400 0000 0000 0000 mode....$.......
00000080 5045 0000 4C01 0500 6591 4635 0000 0000 PE..L...e.F5....
00000090 0000 0000 E000 0E01 0B01 030A 0040 0000 .............@..
000000A0 0074 0000 0000 0000 CC10 0000 0010 0000 .t..............
000000B0 0050 0000 0000 4000 0010 0000 0010 0000 .P....@.........
000000C0 0400 0000 0000 0000 0400 0000 0000 0000 ................
=>Ce que l'on voit (en gros) au début de tout executable, avec la
fameuse phrase
"This program cannot be run in DOS mode".
"PARTIE DE ZEROS"
(Je l'appelle comme ça, on vera après ce que c'est)
00000390 0000 0000 0000 0000 0000 0000 0000 0000 ................
000003A0 0000 0000 0000 0000 0000 0000 0000 0000 ................
000003B0 0000 0000 0000 0000 0000 0000 0000 0000 ................
000003C0 0000 0000 0000 0000 0000 0000 0000 0000 ................
000003D0 0000 0000 0000 0000 0000 0000 0000 0000 ................
000003E0 0000 0000 0000 0000 0000 0000 0000 0000 ................
000003F0 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000400 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000410 0000 0000 0000 0000 0000 0000 0000 0000 ................
=>Ca, ca apparait très souvent et c'est très pratique. Cela permet de bricoler, bricoler, bricoler :)) Ici cela apparait de manière flagrante sur plusieurs lignes, mais cela peut être aussi très court, du genre (là où c'est en rouge) :
6865 6C6C 6F2C 2077 6F72 6C64 0A00 0000"PARTIE DE CODE"
(Là aussi, on verra après)
000017C0 00E8 320D 0000 E9E2 0000 003D FFFF 0000 ..2........=....
000017D0 7421 83F8 0274 1C83 F805 7417 83F8 0774 t!...t....t....t
000017E0 123D 0410 0000 7412 3D05 1000 000F 85BA .=....t.=.......
000017F0 0000 003D 0410 0000 7507 A1AC 5040 00EB ...=....u...P@..
00001800 05A1 5850 4000 6A10 6A00 50FF 3564 5040 ..XP@.j.j.P.5dP@
00001810 00FF 3500 5040 00E8 C10B 0000 E98C 0000 ..5.P@..........
00001820 00A1 5050 4000 8D8D C0FE FFFF 5051 FF15 ..PP@.......PQ..
00001830 D463 4000 C705 2850 4000 0100 0000 6850 .c@...(P@.....hP
00001840 5640 00E8 3036 0000 85C0 7433 6A01 8D85 V@..06....t3j...
00001850 C0FE FFFF 50FF 7508 E851 1900 0085 C074 ....P.u..Q.....t
00001860 1E8D 85C0 FEFF FF50 68A0 5640 00FF 15D4 .......Ph.V@....
=>Bon bien ici, c'est du code pur et dur, comme par exemple où l'on patch un saut quand on cracke.
"PARTIE DE FONCTIONS/DONNEES"
(Là aussi, on verra...)
00006640 6E64 436C 6F73 6500 A300 4669 6E64 4669 ndClose...FindFi
00006650 7273 7446 696C 6541 0000 DB02 6C73 7472 rstFileA....lstr
00006660 636D 7041 0000 3901 4765 7450 726F 6669 cmpA..9.GetProfi
00006670 6C65 5374 7269 6E67 4100 E702 6C73 7472 leStringA...lstr
00006680 6C65 6E41 0000 1702 5274 6C4D 6F76 654D lenA....RtlMoveM
00006690 656D 6F72 7900 E402 6C73 7472 6370 796E emory...lstrcpyn
000066A0 4100 BD01 4C6F 6361 6C52 6541 6C6C 6F63 A...LocalReAlloc
000066B0 0000 BC01 4C6F 6361 6C4C 6F63 6B00 B601 ....LocalLock...
000066C0 4C6F 6361 6C41 6C6C 6F63 0000 C001 4C6F LocalAlloc....Lo
000066D0 6361 6C55 6E6C 6F63 6B00 D002 5F6C 636C calUnlock..._lcl
000066E0 6F73 6500 D502 5F6C 7772 6974 6500 5F00 ose..._lwrite._.
000066F0 4465 6C65 7465 4669 6C65 4100 D102 5F6C DeleteFileA..._l
=>Là vous avez un passage "lisible". On reconnait des noms de fonctions/APIs...
"PARTIE DE FONCTIONS/DONNEES"
(Là aussi, on verra...)
0000A1D0 1B00 2600 5200 6500 7400 6F00 7500 7200 ..&.R.e.t.o.u.r.
0000A1E0 2000 E000 2000 6C00 6100 2000 6C00 6900 ... .l.a. .l.i.
0000A1F0 6700 6E00 6500 2000 6100 7500 7400 6F00 g.n.e. .a.u.t.o.
0000A200 6D00 6100 7400 6900 7100 7500 6500 0000 m.a.t.i.q.u.e...
0000A210 8000 2500 4300 2600 6800 6F00 6900 7300 ..%.C.&.h.o.i.s.
0000A220 6900 7200 2000 6C00 6100 2000 7000 6F00 i.r. .l.a. .p.o.
0000A230 6C00 6900 6300 6500 2E00 2E00 2E00 0000 l.i.c.e.........
0000A240 1000 2600 5200 6500 6300 6800 6500 7200 ..&.R.e.c.h.e.r.
0000A250 6300 6800 6500 0000 0000 0300 2600 5200 c.h.e.......&.R.
0000A260 6500 6300 6800 6500 7200 6300 6800 6500 e.c.h.e.r.c.h.e.
=>... ici, ce sont les menus du programme. Pour ceux qui codent, on remarque le "&" pour souligner une lettre pour les raccourcis...
"PARTIE DE FONCTIONS/DONNEES"
(Là aussi, on verra...)
0000AC30 6900 6F00 6E00 2E00 2000 5100 7500 6900 i.o.n... .Q.u.i.
0000AC40 7400 7400 6500 7A00 2000 7500 6E00 6500 t.t.e.z. .u.n.e.
0000AC50 2000 6F00 7500 2000 7000 6C00 7500 7300 .o.u. .p.l.u.s.
0000AC60 6900 6500 7500 7200 7300 2000 6100 7000 i.e.u.r.s. .a.p.
0000AC70 7000 6C00 6900 6300 6100 7400 6900 6F00 p.l.i.c.a.t.i.o.
0000AC80 6E00 7300 2000 7000 6F00 7500 7200 2000 n.s. .p.o.u.r. .
0000AC90 6C00 6900 6200 E900 7200 6500 7200 2000 l.i.b...r.e.r. .
0000ACA0 6400 6500 2000 6C00 6100 2000 6D00 E900 d.e. .l.a. .m...
0000ACB0 6D00 6F00 6900 7200 6500 2C00 2000 7000 m.o.i.r.e.,. .p.
0000ACC0 7500 6900 7300 2000 6500 7300 7300 6100 u.i.s. .e.s.s.a.
0000ACD0 7900 6500 7A00 2000 E000 2000 6E00 6F00 y.e.z. ... .n.o.
0000ACE0 7500 7600 6500 6100 7500 2E00 6A00 4C00 u.v.e.a.u...j.L.
0000ACF0 6500 2000 6600 6900 6300 6800 6900 6500 e. .f.i.c.h.i.e.
=>... et là, la partie de toutes les chaines de caractères qui sont manipulées par le soft. Elle se trouve à la fin en général.
Bon voilà, on a à peu près fait le tour. On va maintenant passer le soft en revue ligne par ligne et regarder en détail la signification.
On revient donc au début du soft.
00-7F : 1er bloc
------------
(Par 00-7F j'entend: "bloc allant de l'adresse 0x00 à l'adresse 0x7F". Pareil pour les parties suivantes)
00000000 4D5A 9000 0300 0000 0400 0000 FFFF 0000
MZ..............
00000010 B800 0000 0000 0000 4000 0000 0000 0000 ........@.......
00000020 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000030 0000 0000 0000 0000 0000 0000 8000 0000
................
00000040 0E1F BA0E 00B4 09CD 21B8 014C CD21 5468 ........!..L.!Th
00000050 6973 2070 726F 6772 616D 2063 616E 6E6F is program canno
00000060 7420 6265 2072 756E 2069 6E20 444F 5320 t be run in DOS
00000070 6D6F 6465 2E0D 0D0A 2400 0000 0000 0000 mode....$.......
Cette partie s'appelle l'entête MS-DOS. Elle porte aussi le nom d'entête Real-Mode. Elle est au début du fichier, car si celui-ci n'est pas executable sous DOS mais sous Windows uniquement, elle affiche "This program cannot be run in DOS mode" au lieu de mettre un truc barbare du style "The name specified is not recognized as an internal or external command, operable program or batch file". C'est ce qui se passerait en commençant directement avec l'entête PE (voir bloc suivante).
Dans tout ce bloc, le plus important à retenir est ceci :
| Adrs | Nom | Description |
| 00-01 | e_magic MZ : | Ces
2 lettres caractérisent un en-tête DOS (i.e. un soft qui marche sous windows) |
| 3C-3D | e_lfanew 0x8000 : | Lire
0x0080. Cette adresse en 0x3C est un pointeur qui saute sur l'entête PE (voir section suivante). |
Petite précision : bien évidemment, il ne suffit pas de mettre MZ (avec un éditeur hexa) au début d'un fichier pour qu'il "marche tout seul" sous windows...
MZ s'appelle le "Magic Number" est correspond à ce qu'on appelle le format d'image (d'un exe, dll, vxd...).
On définit ainsi plusieurs "magic numbers" :
| IMAGE_DOS_SIGNATURE 0x4D5A | MZ pour les fichiers exe DOS, Windows |
| IMAGE_OS2_SIGNATURE 0x4E45 | NE pour les exes sous OS/2 |
| IMAGE_OS2_SIGNATURE_LE 0x4C45 | LE idem |
| IMAGE_VXD_SIGNATURE 0x454C | LE pour les vxd |
| IMAGE_NT_SIGNATURE 0x50450000 | PE00 pour l'entête PE des exes sous DOS, Windows |
Il est à noter que
les exes de OS/2 ont la même structure que les executables windows.
La syntaxe de
programmation est donnée de la manière suivante :
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
00000000
4D5A 9000 0300 0000 0400 0000 FFFF 0000 MZ..............
00000010 B800 0000 0000 0000 4000 0000 0000 0000 ........@.......
00000020 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000030 0000 0000 0000 0000 0000 0000 8000 0000
................
00000040 0E1F BA0E 00B4 09CD 21B8 014C CD21 5468 ........!..L.!Th
00000050 6973 2070 726F 6772 616D 2063 616E 6E6F is program
canno
00000060 7420 6265 2072 756E 2069 6E20 444F 5320 t be
run in DOS
00000070 6D6F 6465 2E0D 0D0A 2400 0000 0000 0000
mode....$.......
Ensuite vous avez la fameuse phase à 2 Francs "This program cannot be run in DOS mode" qui se termine en 0x73. Elle est suivit de 2E 0D 0D 0A 24 et puis des zéros. Vous avez ensuite la ligne 0x80 qui commence avec PE, mais ça c'est pour après avec la section suivante.
Entre MZ et la phrase "...DOS mode" il y a différentes variables que je n'aborderai pas ici hormis celle en 0x3C qui vaut 0x80. Il s'agit du pointeur (saut) qui indique ou se trouve l'entête PE dans le soft. Quand le programme est chargé en mémoire, l'ordi lit ce bloc, et arrivé en 0x3C il sait qu'il doit aller à l'adresse 0x80 pour lire le PE.
PADDING : ce terme est important. Il signifie "remplissage avec des 0"
C'est ce que l'on a a la ligne 0x70. Apès le 0x24 en 0x78, on termine la ligne par des "00 00". C'est ce dont je parlais plus haut dans la présentation des différents blocs. Ce remplissage peut faire quelques bytes ou bien des blocs entiers. Mais, me direz-vous, "pourquoi mettre des 00 au lieu de placer le code directement à la suite?". Bonne question mon cher Watson! Dans le cas de la ligne, c'est pour avoir une ligne complete et faire commencer le bloc suivant à la ligne. On peut ainsi traiter les blocs par adresse de multiple de 16 pour le mode 32 bits. Quant aux blocs entiers de 00, c'est pour remplir la place (la partie de code non occupée) entre la fin du code dans une section et le début de la section suivante. Et pourquoi ne pas rapprocher les blocs au lieu de mettre tant de 00 ? Et bien comme cela, nous (coders, reversers) avons un espace de liberté où nous pouvons nous exprimer! :o) Valà... De plus, le padding n'est pas qu' "ésthetique". Certaines sections ont besoins d'avoir une certaine taille pour marcher sous une version donnée de windows. Donc retenez que le remplissage avec des zéros pour garder une "structure" dans un exe s'appelle le padding.
80-FFF : 2e bloc
-------------
00000080 5045 0000 4C01 0500
6591 4635 0000 0000 PE..L...e.F5....
00000090 0000 0000 E000 0E01 0B01 030A 0040 0000 .............@..
000000A0 0074 0000 0000 0000 CC10 0000 0010 0000 .t..............
000000B0 0050 0000 0000 4000 0010 0000 0010 0000 .P....@.........
000000C0 0400 0000 0000 0000 0400 0000 0000 0000 ................
000000D0 00E0 0000 0004 0000 8918 0100 0200 0000 ................
000000E0 0000 1000 0010 0000 0000 1000 0010 0000 ................
000000F0 0000 0000 1000 0000 0000 0000 0000 0000 ................
00000100 0060 0000 8C00 0000 0070 0000 8C55 0000 .`.......p...U..
00000110 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000120 00D0 0000 3C09 0000 0000 0000 0000 0000 ....<...........
00000130 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000140 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000150 0000 0000 0000 0000 E062 0000 4002 0000 .........b..@...
00000160 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000170 0000 0000 0000 0000 2E74 6578 7400 0000 .........text...
00000180 9C3E 0000 0010 0000 0040 0000 0010 0000 .>.......@......
00000190 0000 0000 0000 0000 0000 0000 2000 0060 ............ ..`
000001A0 2E64 6174 6100 0000 4C08 0000 0050 0000 .data...L....P..
000001B0 0010 0000 0050 0000 0000 0000 0000 0000 .....P..........
000001C0 0000 0000 4000 00C0 2E69 6461 7461 0000 ....@....idata..
000001D0 E80D 0000 0060 0000 0010 0000 0060 0000 .....`.......`..
000001E0 0000 0000 0000 0000 0000 0000 4000 0040 ............@..@
000001F0 2E72 7372 6300 0000 0060 0000 0070 0000 .rsrc....`...p..
00000200 0060 0000 0070 0000 0000 0000 0000 0000 .`...p..........
00000210 0000 0000 4000 0040 2E72 656C 6F63 0000 ....@..@.reloc..
00000220 9C0A 0000 00D0 0000 0010 0000 00D0 0000 ................
00000230 0000 0000 0000 0000 0000 0000 4000 0042 ............@..B
00000240 0000 0000 0000 0000 0000 0000 0000 0000
................
[...]
00000FE0 0000 0000 0000 0000 0000 0000 0000 0000
................
00000FF0 0000 0000 0000 0000 0000 0000 0000 0000
................
De 0x240 à 0xFFF, il n'y a que des zéros . Il s'agit du padding jusqu'au début de la section suivante.
Bien. Nous sommes donc en 0x80 suite au saut en 0x3C de la section précédente. On lit à cette adresse " PE" qui signifie portable executable. On aborde là une notion très importante dans le monde des exes sous zindoz.
Le format de fichier PE est un format pour les exes et les dlls pour les systèmes d'exploitation de zindoz 95 à ultérieurs. On trouve ce nombre 0x 5045 (PE) sous l'appellation IMAGE_NT_SIGNATURE.
L'entête PE est au programme ce que la table des matières est au livre. Vous voyez dans le code ci-dessus les mots "text", "data", "idata", "rsrc" et "reloc". Ces mots sont en fait nommés avec un point devant ".text", ".data", ".idata", ".rsrc" et ".reloc", bien que le "." ne soit pas indispensable. Ils correspondent chacun à une section de l'exe. Il y a donc 5 sections dans cet exe. Parfois on en trouve plus, parfois moins. Cela dépend de chaque programme. De même, leur nom n'est pas figé dans l'appellation. On peut très bien le changer, où introduire une section avec un nom comme vous voulez. Il faut au maximum sept lettres (soit huit avec le "."), sinon on empiète sur les informations de la section et le programme ne va pas aimer! On va d'ailleurs traiter un petit exemple plus bas :)
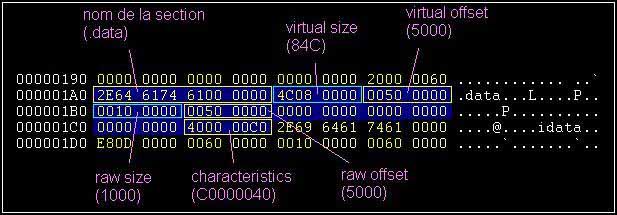
Chaque section définie dans le PE est codée sur 0x28 bytes (Attention, on est en hexa! Je rappelle qu'un byte ça prend "00" en place). Par exemple pour la section .data, on a (en bleu) :
La manière la plus classique et facile pour visualiser ces informations,
est d'utiliser procdump.
Lancez le, appuyez ensuite sur "PE EDITOR", choisissez votre
exe (le notepad), appuyez ensuite sur "Sections" dans la nouvelle
fenêtre qui vient de s'ouvrir. On obtient les informations de l'image
ci-dessus.
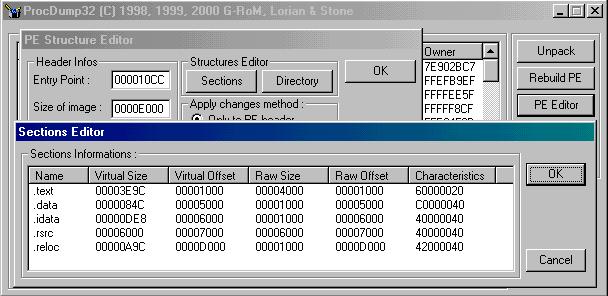
Bien, voyons de plus près la signification de tout cela...
Sections Informations :
| Name | Virtual Size | Virtual Offset | Raw Size | Raw Offset | Characteristics |
| .text | 00003E9C | 00001000 | 00004000 | 00001000 | 60000020 |
| .data | 0000084C | 00005000 | 00001000 | 00005000 | C0000040 |
| .idata | 00000DE8 | 00006000 | 00001000 | 00006000 | 40000040 |
| .rsrc | 00006000 | 00007000 | 00006000 | 00007000 | 40000040 |
| .reloc | 00000A9C | 0000D000 | 00001000 | 0000D000 | 42000040 |
Je traite l'exemple avec .text, c'est bien sûr valable pour toutes les sections.
La section commence au "Virtual Offset" en 0x1000 (vérifiez le sous un éditeur hexa en allant à cette adresse). Ensuite, on a la taille de cette section en "Virtual Size" qui vaut 0x3E9C. La taille indiquée ici correspond à la place effectivement occupée par du code. Mais comme il y a du padding entre les sections, la taille réelle de la section est plus grande. Cette taille réelle est donnée en "Raw Size". Il s'agit de la différence entre le début de la section suivante (.data en 0x5000) moins le début de notre section (.text en 0x1000) qui fait donc 0x4000. En dans ces 0x4000 bytes, on a 0x3E9C bytes (de la virtual size) qui sont du code, et le reste du padding, soit 0x4000 - 0x3E9C = 0x164 bytes de "00".
Donc, on retient les définitions ci-dessus, et le fait que la raw size = virtual size + padding. Donc la raw size est supérieure à la virtual size. On retrouve la propriété du padding où tous les nombres de la raw size sont "ronds" i.e. un multiple du 16, 32 ou 64 bits.
Pour la "Raw Offset", cela correspond dans le cas du Notepad à la "Virtual Offset". Mais ceci est rarement le cas, ce qui en général complique un peu les choses. Par exemple, si on regarde les sections de Procdump lui-même :
Sections Informations :
| Name | Virtual Size | Virtual Offset | Raw Size | Raw Offset | Characteristics |
| .text | 000088B2 | 00001000 | 00008A00 | 00000400 | 60000020 |
| .data | 00008961 | 0000A000 | 00002800 | 00008E00 | C0000040 |
| .idata | 00000A84 | 00013000 | 00000C00 | 0000B600 | C0000040 |
| .rsrc | 00002AC0 | 00014000 | 00002C00 | 0000C200 | 40000040 |
| .reloc | 00001284 | 00017000 | 00001400 | 0000EE00 | 42000040 |

On remarque ici que l'on ne peut plus lire directement l'offset sous l'éditeur hexa à partir du dead listing
(0x4098A6 donne 0x98A6 qui est différent de 0x8CA6). On utilise en fait la formule suivante qui est applicable à tous les cas :
L'adresse 0x8CA6 est dans la section .text. Il suffit
de regarder la colonne Virtual Offset pour cela.
Pour l'obtenir (à l'ImageBase près), on fait donc :
0x408CA6 = 0x4098A6 - 0x1000 + 0x400
Et le 0x4098A6 que l'on lit sous wdasm ou bien sous softice est appelé le RVA (Relative Virtual Offset). Cette valeur est utilisée pour l'offset (du soft) en mémoire (dans la RAM) quand l'ImageBase est inconnue. Bon, bien maintenant que l'on a vu le petit calcul, ce n'est plus trés bien compliqué...
La dernière colonne "Characteristics" indique les propriétés de la section. Ces propriétés sont divisées en deux.
Execute, Read, Write
***************************
0x20000000 = IMAGE_SCN_MEM_EXECUTE : La section peut être executée
comme du code
0x40000000 = IMAGE_SCN_MEM_READ
: La section peut être lue
0x80000000 = IMAGE_SCN_MEM_WRITE
: On peut écrire dans la section (lorsqu'elle est en mémoire)
On peut avoir des combinaisons de propriétés pour une section. Pour ceux d'entre vous qui ont l'habitude de la gestion des droits des fichiers sous Unix (avec 1,2,4), on a la même procédure ici mais en hexadécimal, par exemple :
| 20000000 | 20000000 | 20000000 | 40000000 | 40000000 | 80000000 |
| 40000000 | 40000000 | 80000000 | |||
| 80000000 | |||||
| -------- | -------- | -------- | -------- | -------- | -------- |
| 20000000 | 60000000 | E0000000 | 40000000 | C0000000 | 80000000 |
| Execute | Execute | Execute | Read | Read | Write |
| +Read | + Read | +Write | |||
| + Write |
Code, Data
**************
| 0x00000020 = IMAGE_SCN_CNT_CODE | La section contient du code executable |
| 0x00000040 = IMAGE_SCN_CNT_INITIALIZED_DATA | La section contient des données initialisées |
| 0x00000080 = IMAGE_SCN_CNT_UNINITIALIZED_DATA | La section contient des données non initialisées |
Même calcul ici :
| 00000020 | 00000020 | 00000020 | 00000040 | 00000040 | 00000080 |
| 00000040 | 00000040 | 00000080 | |||
| 00000080 | |||||
| -------- | -------- | -------- | -------- | -------- | -------- |
| 00000020 | 00000060 | 000000E0 | 00000040 | 000000C0 | 00000080 |
| Code | Code | Code | I-Data | I-Data | U-Data |
| +I-Data | +I-Data | +U-Data | |||
| +U-Data |
Mais ces quelques
caractéristiques ne sont pas les seules qui existent.
Ce sont bien sûr les plus courantes dans le cas qui nous intérese, mais
il en existe d'autres :
| 0x00000008 = IMAGE_SCN_TYPE_NO_PAD | Pas
de padding jusqu'à la prochaine limite (pour les fichiers .obj seulement) |
| 0x00000200 = IMAGE_SCN_LNK_INFO | La
section contient des infos ou des commentaires (pour .obj seulement) |
| 0x00000800 = IMAGE_SCN_LNK_REMOVE | La
section ne devient pas une partie de l'image (pour .obj seulement) |
| 0x00001000 = IMAGE_SCN_LNK_COMDAT | La
section contient des données COMDAT (pour .obj seulement) |
| 0x00@00000 = IMAGE_SCN_ALIGN_@BYTES | Aligne les données sur une limite de @ byte(s) (@=1,2,4,8,16,32,64) |
| 0x01000000 = IMAGE_SCN_LNK_OVFL | La section contient des "extended relocations" |
| 0x02000000 = IMAGE_SCN_MEM_DISCARDABLE | La section peut être annulée à volonté |
| 0x04000000 = IMAGE_SCN_MEM_NOT_CACHED | La section ne peut être "cached" (processeur) |
| 0x08000000 = IMAGE_SCN_MEM_NOT_PAGED | La section ne peut être "pageable" |
| 0x10000000 = IMAGE_SCN_MEM_SHARED | La section peut être partagée en mémoire |
De plus, il y a également
des propriétés non encore utilisées mais déjà réservées pour le futur!!
Elles ne sont donc pas attribuées...
0x00000000
= IMAGE_SCN_TYPE_REG
0x00000001 = IMAGE_SCN_TYPE_DSECT
0x00000002 = IMAGE_SCN_TYPE_NOLOAD
0x00000004 = IMAGE_SCN_TYPE_GROUP
0x00000010 = IMAGE_SCN_TYPE_COPY
0x00000100 = IMAGE_SCN_LNK_OTHER
0x00000400 = IMAGE_SCN_TYPE_OVER
0x00008000 = IMAGE_SCN_MEM_FARDATA
0x00020000 = IMAGE_SCN_MEM_PURGEABLE
0x00020000 = IMAGE_SCN_MEM_16BIT
0x00040000 = IMAGE_SCN_MEM_LOCKED
0x00080000 = IMAGE_SCN_MEM_PRELOAD
Si on veut donc se rajouter une section dans un exe (ou en modifier une existante), il sera avantageux de lui coller le maximum : un 0xE0000020 comme caractéristique.
Bien! On a fini pour les "characteristics", on va passer à notre petit exemple de ...bien plus haut :) (NDOracle (mise en page): Ouf!)
Il s'agit de rajouter une section à l'exe pour se faire la main en manipulant les données des sections. Pourquoi rajouter une section? Et bien parfois, on n'a pas assez de place dans les paddings d'un exe, et il est bon de se tailler soi-même sa place :) Autre avantage, quand on écrit du code dans le padding, on est par définition en dehors de la virtual size, donc si vous désassemblez le fichier, vous ne verrez pas votre code.
Pour rajouter une nouvelle section, on va faire cela d'abord
"automatiquement" avec procdump. Puis, comme on est pas esclave
d'un programme qui fait les choses à notre place, on va le faire "à
la main" avec un éditeur hexa pour bien savoir comment cela marche!
Zou...
Vous avez la copie du notepad dans un repertoire. Renommez
la N0.exe (par exemple, c'est ce que j'ai fait).
Celle-là, on n'y touche pas, elle va servir pour faire des comparaisons.
Faites en une copie, soit N1.exe, et une 2eme copie, soit N2.exe.
On va utiliser procdump pour N1.exe et on va faire N2.exe à la main.
Procdump
*************
Dans la fenêtre où les sections sont affichées, cliquer avec le bouton droit de la souris sur une section et choisir "Add section". Rentrer un nom (7 lettres max.) et appuyez sur OK. Procdump rajoute automatiquement la nouvelle section à la fin et caclule les virtual/raw offsets. La caractéristique par défaut est 0xC0000040. Il ne reste plus qu'à éditer la section pour y modifier ses valeurs. Au passage, la taille de l'exe passe de 56 à 60Ko. Voilà pour la méthode "automatique".
A la main
************
On part du principe qu'on ne sait rien, et qu'on veut apprendre. Comment rajoute-t-on une section? On peut déjà commencer à calquer notre section à la suite des autres. Ainsi, j'appelle ma section ".anubis", je la mets après la dernière section du notepad, soit .reloc. Son virtual offset sera donc de (= raw size + raw offset) E000. Et on va dire qu'elle fait 1000 en taille, donc de vitual size. Ici on n'a pas besoin de padding puisq'on a une section toute vide. Et pour les caractéristiques, on prendre les même que .rsrc et .idata soit 0x40000040. N'oubliez pas que la déclaration de la section se fait sur 0x28 bytes. On commence donc à l'offset 0x240.
En écrivant par analogie (par exemple avec .rsrc) dans le PE sous l'éditeur hexa, on a ceci :
000001F0 2E72 7372 6300
0000 0060 0000 0070 0000 .rsrc....`...p..
00000200 0060 0000 0070 0000 0000 0000 0000 0000 .`...p..........
00000210 0000 0000 4000 0040 2E72 656C 6F63 0000 ....@..@.reloc..
00000220 9C0A 0000 00D0 0000 0010 0000 00D0 0000 ................
00000230 0000 0000 0000 0000 0000 0000 4000 0042 ............@..B
00000240 2E61
6E75 6269 7300
0010 0000 00E0 0000 .anubis.........
00000250 0010 0000 00E0 0000 0000 0000 0000 0000 ................
00000260 0000 0000 4000 0040 0000 0000 0000 0000 ....@..@........
Maintenant, sauvez, et regarder N2.exe sous procdump... Rien! Ben oui, il ne s'agit pas d'écrire, il faut aussi dire au programme que quelquechose de nouveau est là. Très certainement il a quelque chose d'autre à changer dans l'en-tête PE.
Comment savoir? On va tout simplement comparer N0.exe et N1.exe, le fichier de référence et celui modifié par procdump.
Pour cela, pas besoin de se taper la comparaison byte à byte dans l'éditeur hexa. Kro$oft nous fournit les moyens rapides et efficaces de le faire. Sortez une fenêtre DOS, on va se taper des bonnes vieilles commandes. Héhé...
La commande DOS "FC" ou FILE COMPARE
*******************************************************
On peut utiliser cette commande de 2 manières simples
:
1) La comparaison des 2 fichiers est
de quelques bytes
=> tapez"fc nom_fichier1.exe nom_fichier2.exe | more"
(NDOracle : Appuyez sur Alt Gr + 6 pour faire le symbole " | "
(barre verticale))
Et vous visualisez à l'écran le résultat.
S'il y a plus de données que la taille de l'écran, une pause est faite
avec "| more"
2) La comparaison est de "beaucoup" de bytes
=> tapez"fc nom_fichier1.exe nom_fichier2.exe > ici.txt"
Et rien ne s'affiche à l'écran, mais tout est redirigé
(>) dans le fichier ici.txt qui est automatiquement créé. Plus facile
à lire par la suite :)
On ne pourra jamais se passer du DOS. C'est la meilleure et la pire des choses
que kro$oft ait faite...
Et puis quelle analogie avec le shell (>, | more...), dès qu'on sort
des DIR et compagnie!
Donc dans notre cas, on tape "fc N0.exe N1.exe > ici.txt"
et on obtient ça :


